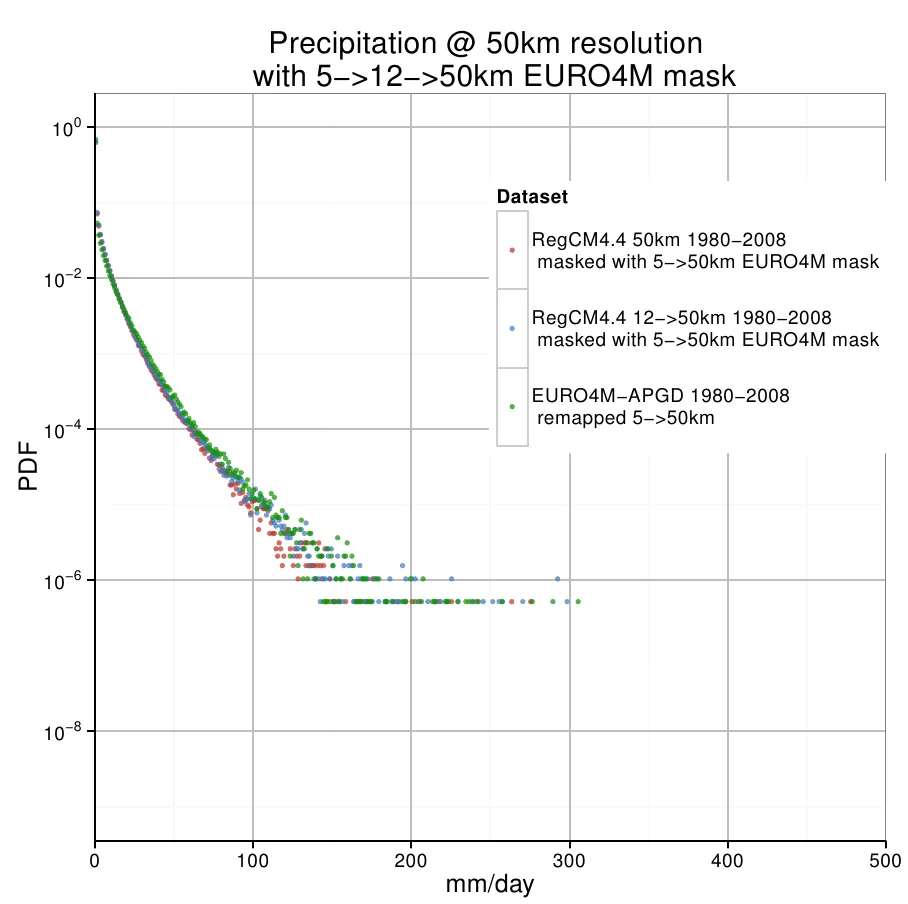
我目前使用R中的ggplot生成以下图表:
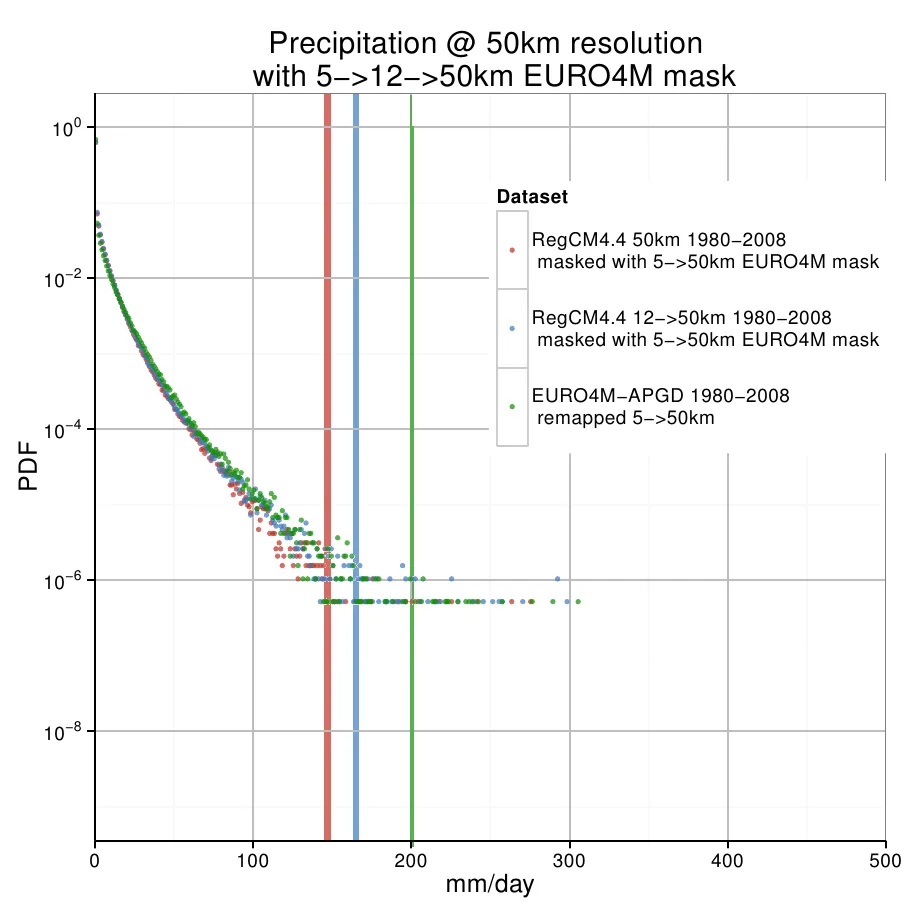
我想要做的是为每个数据集绘制一个颜色编码的垂线,代表95分位数,就像我手动画在下面的例子中一样:
我还尝试过
请注意,密度值非常低,最低可达1e-8。我不知道quantile()函数是否支持这种情况。
我了解到,计算直方图的分位数与计算数字列表的分位数并不完全相同。我不知道它是否有帮助,但是HistogramTools软件包包含一个ApproxQuantile()函数,用于直方图分位数。
下面包含了最小工作示例。正如您所看到的,我从每个直方图获取一个数据框,然后将这些数据框绑定在一起并绘制出来。
我想要做的是为每个数据集绘制一个颜色编码的垂线,代表95分位数,就像我手动画在下面的例子中一样:
+ geom_line(stat="vline", xintercept="mean"),但当然我要找的是分位数,而不是平均值,据我所知,ggplot不允许这样做。颜色没问题。我还尝试过
+ stat_quantile(quantiles = 0.95),但我不确定它究竟是什么。文档非常缺乏。颜色又没问题。请注意,密度值非常低,最低可达1e-8。我不知道quantile()函数是否支持这种情况。
我了解到,计算直方图的分位数与计算数字列表的分位数并不完全相同。我不知道它是否有帮助,但是HistogramTools软件包包含一个ApproxQuantile()函数,用于直方图分位数。
下面包含了最小工作示例。正如您所看到的,我从每个直方图获取一个数据框,然后将这些数据框绑定在一起并绘制出来。
library(ggplot2)
v <- c(1:30, 2:50, 1:20, 1:5, 1:100, 1, 2, 1, 1:5, 0, 0, 0, 5, 1, 3, 7, 24, 77)
h <- hist(v, breaks=c(0:100))
df1 <- data.frame(h$mids,h$density,rep("dataset1", 100))
colnames(df1) <- c('Bin','Pdf','Dataset')
df2 <- data.frame(h$mids*2,h$density*2,rep("dataset2", 100))
colnames(df2) <- c('Bin','Pdf','Dataset')
df_tot <- rbind(df1, df2)
ggplot(data=df_tot[which(df_tot$Pdf>0),], aes(x=Bin, y=Pdf, group=Dataset, colour=Dataset)) +
geom_point(aes(color=Dataset), alpha = 0.7, size=1.5)
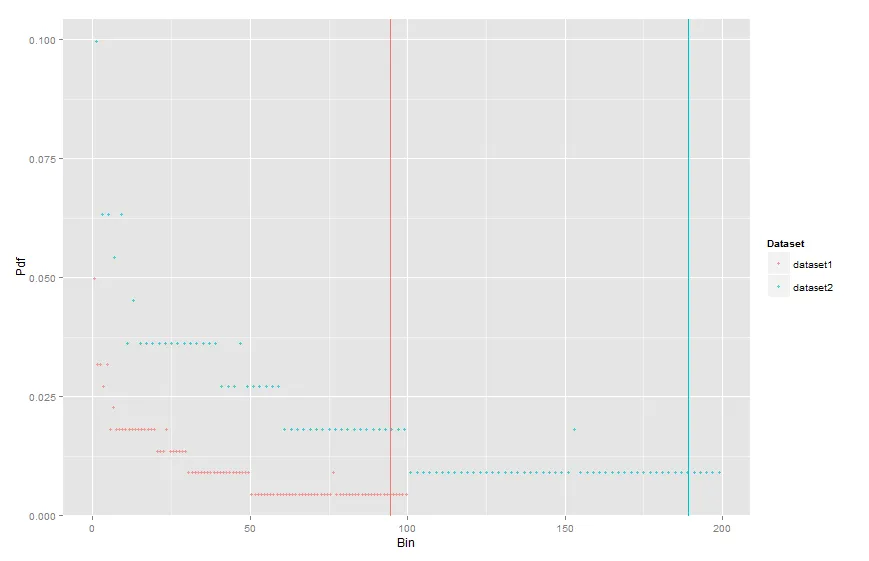
quantile(c(0:100), 0.95)。蓝色数据集同理。不幸的是,在直方图之前,我无法访问整个数据数组,因为它太大而无法放入内存。这就是为什么我需要使用直方图的原因。对于文件的每个层,我创建一个直方图。然后,我使用HistogramTools::AddHistrograms将它们合并成一个单一的直方图。 - AF7geom_vline),请告诉我,我会删除答案。 - tonytonov