我有以下数据。
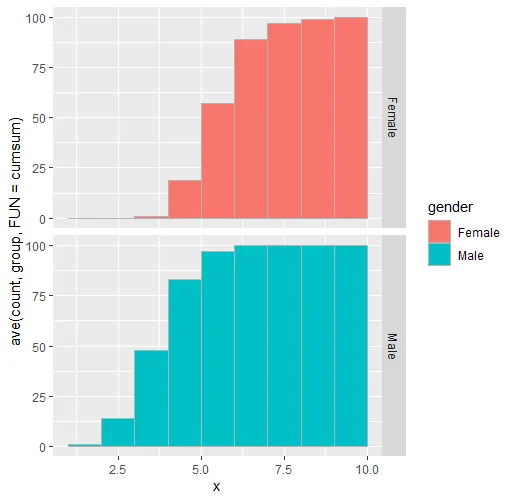
但我得到了这个图表: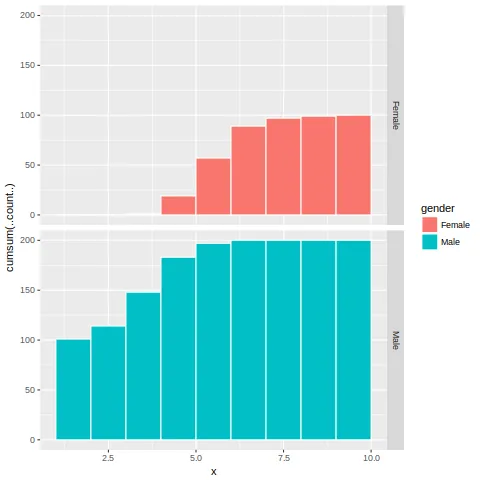 显然,这不正确。如何获得正确的图表呢,就像这样:
显然,这不正确。如何获得正确的图表呢,就像这样:
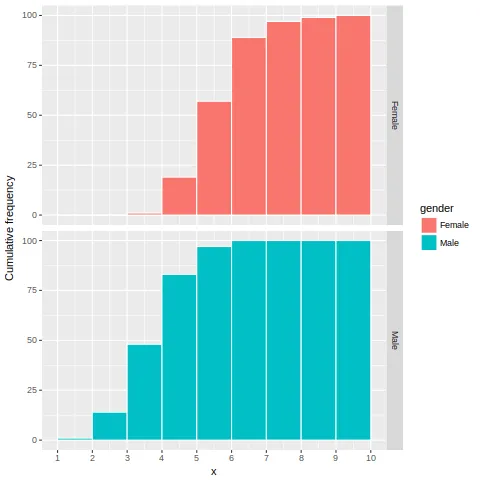 谢谢!
谢谢!
set.seed(123)
x = c(rnorm(100, 4, 1), rnorm(100, 6, 1))
gender = rep(c("Male", "Female"), each=100)
mydata = data.frame(x=x, gender=gender)
我希望使用ggplot绘制两个累积直方图(一个为男性,另一个为女性)。以下是我尝试过的代码:
ggplot(data=mydata, aes(x=x, fill=gender)) + stat_bin(aes(y=cumsum(..count..)), geom="bar", breaks=1:10, colour=I("white")) + facet_grid(gender~.)
但我得到了这个图表:
显然,这不正确。如何获得正确的图表呢,就像这样:
谢谢!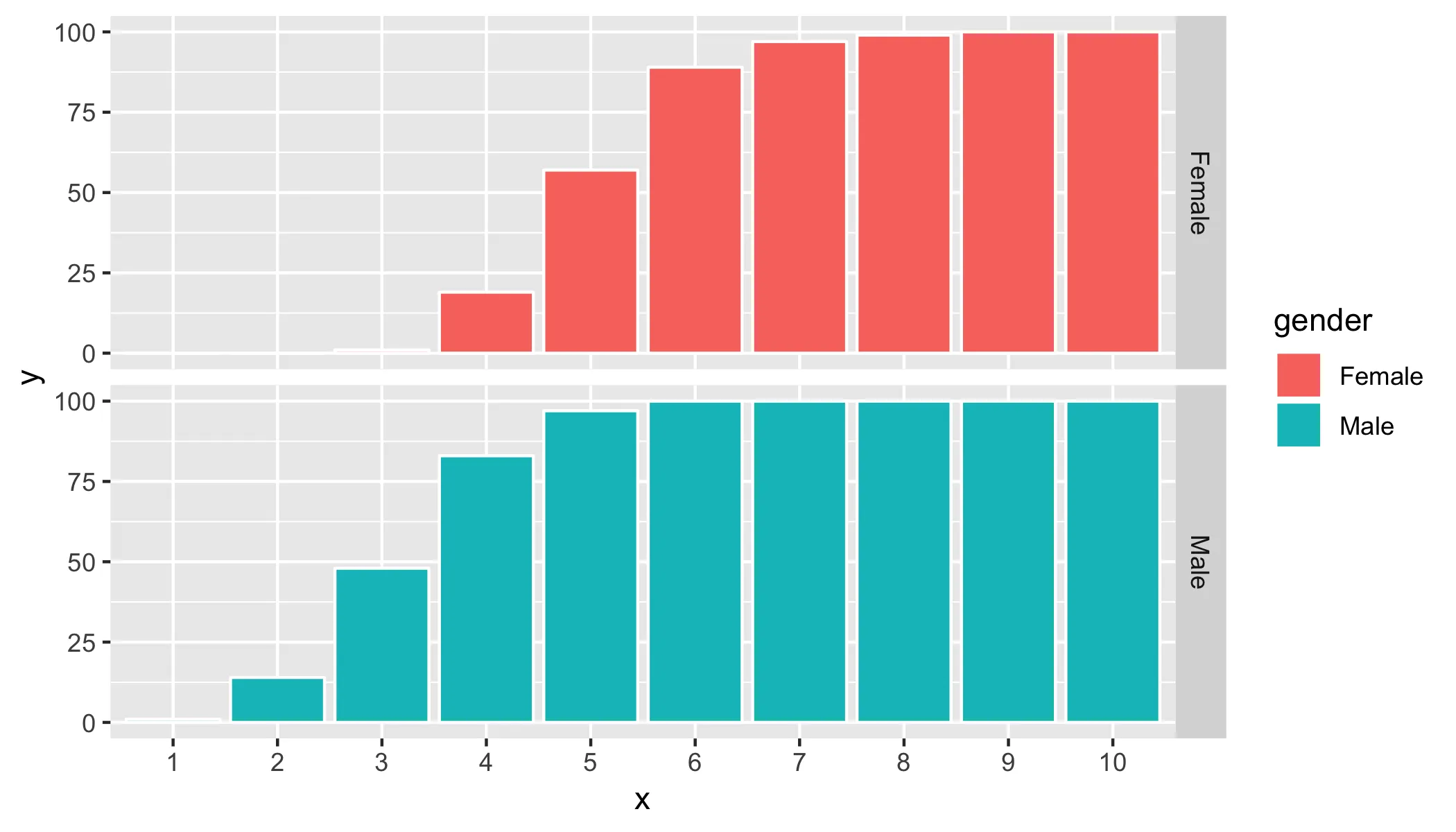
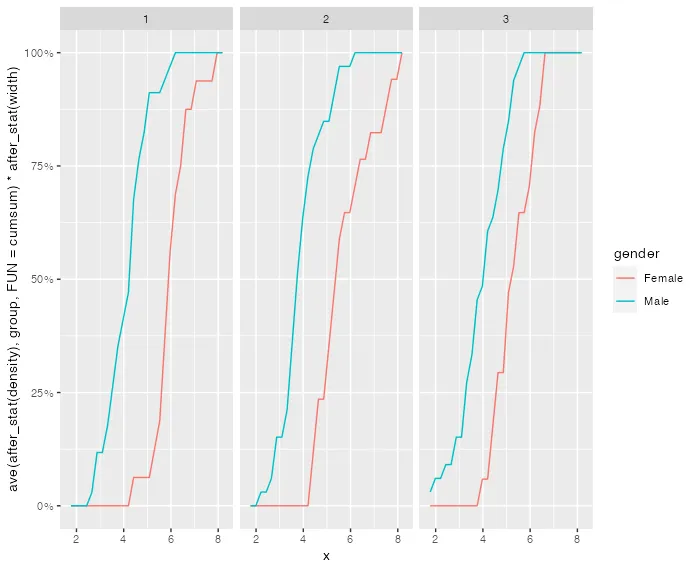
ggplot内进行数据操作是不好的实践,我肯定不会称之为更简单的解决方案,但这显然是你的选择。” - Maurits Evers