我还没有找到一种全面的方法来做到这一点,所以在这里给出了一个解决方案:
def add_multindex_level(
data: pd.DataFrame,
keys: Union[Any, List[Any]],
level: int=0,
axis: int=0,
name: str=None,
inplace: bool=False,
) -> pd.DataFrame:
to_promote = data.columns if axis==1 else data.index
keys = [keys]*len(to_promote) if isinstance(keys, str) else keys
if len(keys)!=len(to_promote):
raise ValueError(
"Keys must be a value or array-like matching the length of the index to extend"
)
new_keys = []
for existing_key,insert_key in zip(to_promote, keys):
if isinstance(existing_key, tuple):
new_key = (*existing_key[:level], insert_key, *existing_key[level:])
else:
new_key = (existing_key, insert_key) if level else (insert_key, existing_key)
new_keys.append(new_key)
data_ = data if inplace else data.copy(deep=True)
new_index = pd.MultiIndex.from_tuples(new_keys)
new_names = []
for l in range(new_index.nlevels):
if l==level:
n = name
else:
n = to_promote.names[l - (1 if l>=level else 0)]
new_names.append(n)
new_index.names = new_names
if axis:
data_.columns = new_index
else:
data_.index = new_index
return None if inplace else data_
>>> source
a b c
0 0 5 0
1 1 6 1
2 0 9 4
>>> add_multindex_level(source, ['x','y','z'], level=1, axis=1)
a b c
x y z
0 0 5 0
1 1 6 1
2 0 9 4
>>> add_multindex_level(source, ['x','y','z'], level=0, axis=1)
x y z
a b c
0 0 5 0
1 1 6 1
2 0 9 4
>>> add_multindex_level(source, 'A', level=0, axis=1)
x y z
A A A
0 0 5 0
1 1 6 1
2 0 9 4
>>> add_multindex_level(source, 'A', level=0, axis=0)
x y z
A 0 0 5 0
A 1 1 6 1
A 2 0 9 4
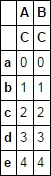
pd.MultiIndex.from_product([df.columns, ['C']]),这样就不必跟踪df.columns的长度了,更加简便。您介意将其添加到答案中,以便我接受吗? - Steven Gpd.MultiIndex.from_product(df.columns.levels + [['C']])可以创建一个多级索引,其中包含df数据框的列级别和额外的 'C' 级别。 - user3556757pd.MultiIndex.from_product([list(df.columns), ['C']])- Max