您可以沿着索引轴将第一个df与第二个df的每一列相乘,这是处理大型数据集的最快方法(见下文):
df = pd.concat([df_1.mul(col[1], axis="index") for col in df_2.iteritems()], axis=1)
# Change the name of the columns
df.columns = ["_".join([i, j]) for j in df_2.columns for i in df_1.columns]
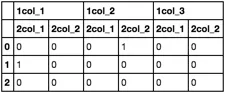
df
1col_1_2col_1 1col_2_2col_1 1col_3_2col_1 1col_1_2col_2 \
0 0 0 0 0
1 1 0 0 0
2 0 0 0 0
1col_2_2col_2 1col_3_2col_2
0 1 0
1 0 0
2 0 0
-->请参考基准测试结果,选择最适合你的数据集的答案。
基准测试
功能:
def Test2(DA,DB):
MA = DA.as_matrix()
MB = DB.as_matrix()
MM = np.zeros((len(MA),len(MA[0])*len(MB[0])))
Col = []
for i in range(len(MB[0])):
for j in range(len(MA[0])):
MM[:,i*len(MA[0])+j] = MA[:,j]*MB[:,i]
Col.append('1col_'+str(i+1)+'_2col_'+str(j+1))
return pd.DataFrame(MM,dtype=int,columns=Col)
def Test3(df_1, df_2):
df = pd.concat([df_1.mul(i[1], axis="index") for i in df_2.iteritems()], axis=1)
df.columns = ["_".join([i,j]) for j in df_2.columns for i in df_1.columns]
return df
def Test4(df_1,df_2):
pidx = np.indices((df_1.shape[1], df_2.shape[1])).reshape(2, -1)
lcol = pd.MultiIndex.from_product([df_1.columns, df_2.columns],
names=[df_1.columns.name, df_2.columns.name])
return pd.DataFrame(df_1.values[:, pidx[0]] * df_2.values[:, pidx[1]],
columns=lcol)
def jeanrjc_imp(df_1, df_2):
df = pd.concat([df_1.mul(i[1], axis="index") for i in df_2.iteritems()], axis=1, keys=df_2.columns)
return df
代码:
抱歉,这段丑陋的代码,最后的情节很重要:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df_1 = pd.DataFrame(np.random.randint(0, 2, (1000, 600)))
df_2 = pd.DataFrame(np.random.randint(0, 2, (1000, 600)))
df_1.columns = ["1col_"+str(i) for i in range(len(df_1.columns))]
df_2.columns = ["2col_"+str(i) for i in range(len(df_2.columns))]
resa = {}
resb = {}
resc = {}
for f, r in zip([Test2, Test3, Test4, jeanrjc_imp], ["T2", "T3", "T4", "T3bis"]):
resa[r] = []
resb[r] = []
resc[r] = []
for i in [5, 10, 30, 50, 150, 200]:
a = %timeit -o f(df_1.iloc[:,:i], df_2.iloc[:, :10])
b = %timeit -o f(df_1.iloc[:,:i], df_2.iloc[:, :50])
c = %timeit -o f(df_1.iloc[:,:i], df_2.iloc[:, :200])
resa[r].append(a.best)
resb[r].append(b.best)
resc[r].append(c.best)
X = [5, 10, 30, 50, 150, 200]
fig, ax = plt.subplots(1, 3, figsize=[16,5])
for j, (a, r) in enumerate(zip(ax, [resa, resb, resc])):
for i in r:
a.plot(X, r[i], label=i)
a.set_xlabel("df_1 columns #")
a.set_title("df_2 columns # = {}".format(["10", "50", "200"][j]))
ax[0].set_ylabel("time(s)")
plt.legend(loc=0)
plt.tight_layout()
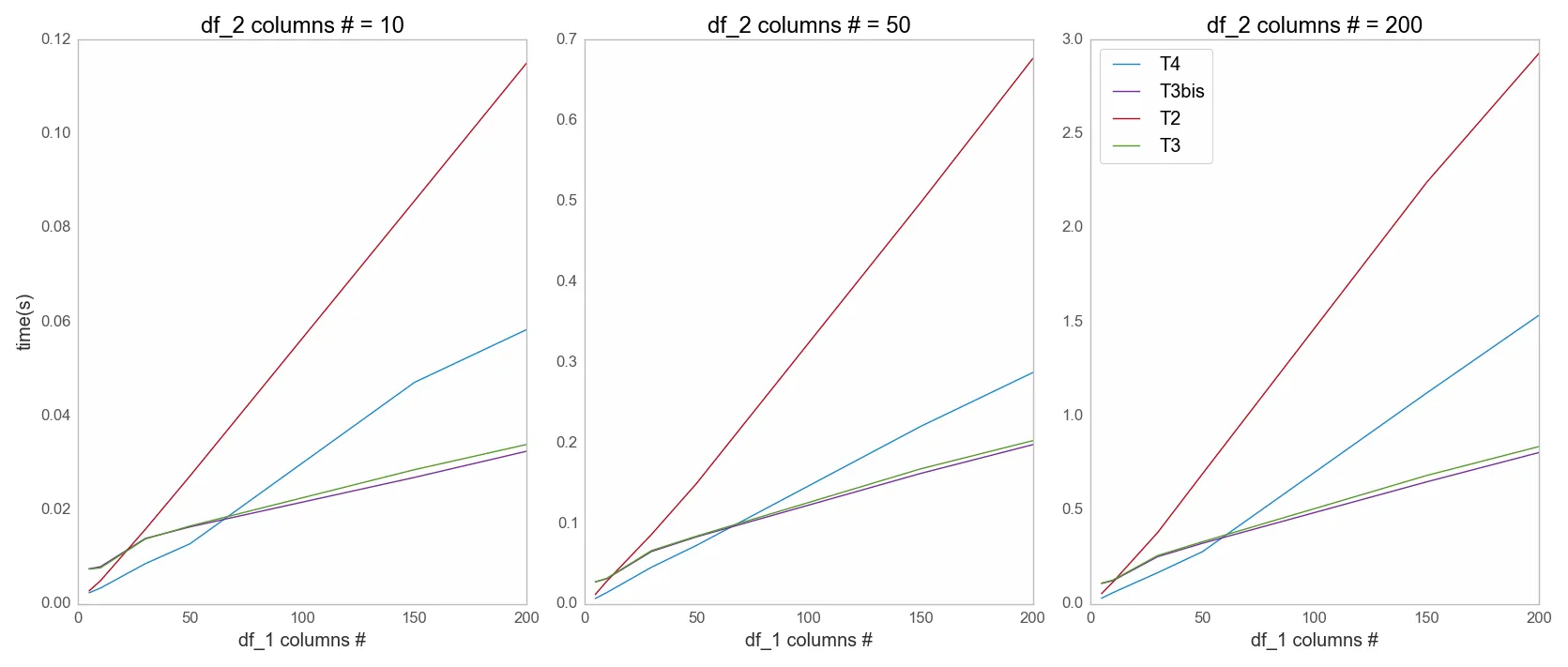
使用 T3b <=> jeanrjc_imp。它比 Test3 更快一些。
结论:
根据您的数据集大小,选择正确的函数,Test4 和 Test3(b)之间。根据 OP 的数据集,Test3 或者 jeanrjc_imp 应该是最快的,也是最短的!
希望对你有帮助。

df1_columns = df1.columns。 - Khris