我想知道是否有可能在同一次调用/循环中同时调用
假设以下数据框:
我希望计算出
调用
我预计这会使搜索效果不佳,因为搜索将被执行两次。
idxmin和min。假设以下数据框:
id option_1 option_2 option_3 option_4
0 0 10.0 NaN NaN 110.0
1 1 NaN 20.0 200.0 NaN
2 2 NaN 300.0 30.0 NaN
3 3 400.0 NaN NaN 40.0
4 4 600.0 700.0 50.0 50.0
我希望计算出
option_ 系列中的最小值 (min) 以及包含它的列 (idxmin)。 id option_1 option_2 option_3 option_4 min_column min_value
0 0 10.0 NaN NaN 110.0 option_1 10.0
1 1 NaN 20.0 200.0 NaN option_2 20.0
2 2 NaN 300.0 30.0 NaN option_3 30.0
3 3 400.0 NaN NaN 40.0 option_4 40.0
4 4 600.0 700.0 50.0 50.0 option_3 50.0
显然,我可以单独调用idxmin和min(一个接一个地,参见下面的例子),但有没有一种更有效的方法,不需要两次搜索矩阵(一次搜索值和另一次搜索索引)?
调用min和idxmin的示例
import pandas as pd
import numpy as np
df = pd.DataFrame({
'id': [0,1,2,3,4],
'option_1': [10, np.nan, np.nan, 400, 600],
'option_2': [np.nan, 20, 300, np.nan, 700],
'option_3': [np.nan, 200, 30, np.nan, 50],
'option_4': [110, np.nan, np.nan, 40, 50],
})
df['min_column'] = df.filter(like='option').idxmin(1)
df['min_value'] = df.filter(like='option').min(1)
我预计这会使搜索效果不佳,因为搜索将被执行两次。
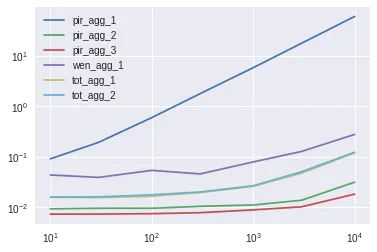
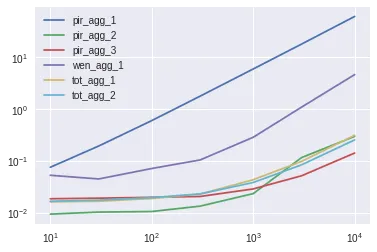
O(1),搜索为O(n)。实际上,直接访问的k似乎非常大,矢量化搜索非常快。我假设直接访问也应该被矢量化了(我错了吗?),在这种情况下,我们比较的是矢量化的搜索和直接访问,再次强调,我的假设可能是错误的。 - toto_tico.lookup()比[]/.iloc()慢,因为它需要标签(而不是索引)。正如你的答案所示,列越多,速度越慢。此外,如果您说明您关心的典型或最大维度范围:10,000列或更多?1,000行或更多?矩阵是否稀疏,您是否关心NaN条目,NaN是否可以稀疏表示?请参见pandas Sparse data structures。 - smci