pandas 从 DataFrame 中选择数据有两种主要方法。
文档使用位置一词来指代整数位置。我不喜欢这个术语,因为我觉得它很容易引起混淆。整数位置更具描述性,正是 .iloc 的含义。关键词在这里是 INTEGER - 选定整数位置时必须使用整数。
在展示总结之前,让我们确保...
.ix 已弃用且模糊不清,不应再使用
pandas 有三个主要的索引器 。我们有索引操作符本身(方括号[]),.loc 和 .iloc。 让我们总结一下:
[] - 主要选择列的子集,但也可以选择行。不能同时选择行和列。.loc - 仅按标签选择行和列的子集.iloc - 仅按整数位置选择行和列的子集
我几乎从不使用.at或.iat,因为它们没有增加任何额外的功能,并且只有轻微的性能提升。除非您有一个时间非常敏感的应用程序,否则我会不鼓励使用它们。无论如何,我们有它们的总结:
.at 仅通过标签在 DataFrame 中选择单个标量值.iat 仅通过整数位置在 DataFrame 中选择单个标量值
除了通过标签和整数位置进行选择外,还存在布尔选择,也称为布尔索引。
以下是说明.loc、.iloc、布尔选择以及.at和.iat的示例
我们首先将重点放在.loc和.iloc之间的区别上。在谈论区别之前,了解DataFrame具有帮助标识每个列和每行的标签非常重要。让我们看一个示例DataFrame:
df = pd.DataFrame({'age':[30, 2, 12, 4, 32, 33, 69],
'color':['blue', 'green', 'red', 'white', 'gray', 'black', 'red'],
'food':['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'height':[165, 70, 120, 80, 180, 172, 150],
'score':[4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'state':['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']
},
index=['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
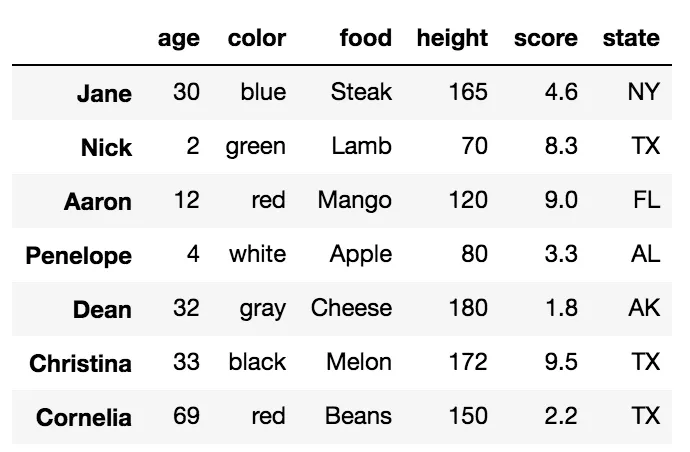
所有加粗的单词都是标签。标签age、color、food、height、score和state用于列。其他标签Jane、Nick、Aaron、Penelope、Dean、Christina、Cornelia用作行的标签。这些行标签的集合称为索引。
主要选择DataFrame中特定行的方法是使用.loc和.iloc索引器。每个索引器也可以用于同时选择列,但现在只关注行更容易。另外,这些索引器都使用一个紧跟其名称的括号集来进行选择。
.loc仅按标签选择数据
我们首先讨论的是.loc索引器,它仅通过索引或列标签选择数据。在我们的示例DataFrame中,我们为索引提供了有意义的名称作为值。许多DataFrame将没有任何有意义的名称,而会默认为从0到n-1的整数,其中n是DataFrame的长度(行数)。
您可以使用
许多不同的输入来使用.loc,其中三个是:
- 字符串
- 字符串列表
- 使用字符串作为起始和停止值的切片表示法
使用字符串选择单个行
要选择单个数据行,请在.loc后面的括号内放入索引标签。
df.loc['Penelope']
这将返回数据行作为一系列数据
age 4
color white
food Apple
height 80
score 3.3
state AL
Name: Penelope, dtype: object
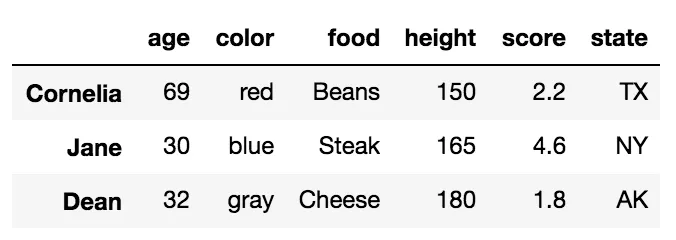
使用字符串列表在.loc中选择多行
df.loc[['Cornelia', 'Jane', 'Dean']]
这将返回一个DataFrame,其中行的顺序按照列表中指定的顺序排列:
使用.loc和切片选择多行
切片记法由开始、结束和步长值定义。在按标签切片时,pandas会将停止值包含在返回结果中。下面的示例从Aaron到Dean(包含这两个标签)进行了切片。步长大小未明确定义,但默认为1。
df.loc['Aaron':'Dean']
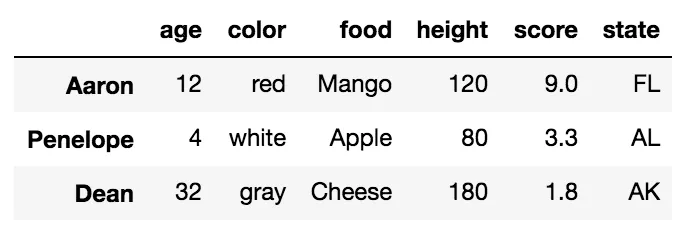
复杂的切片可以像Python列表一样进行。
.iloc 只通过整数位置选择数据
现在让我们转向 .iloc。DataFrame 中的每一行和列都有一个定义它的整数位置。这是除了在输出中可视化显示的标签之外的另一个位置。整数位置简单地从顶部/左侧开始计算,行/列数从0开始。
有许多不同的输入可以用于.iloc,其中三个是:
- 一个整数
- 一个整数列表
- 使用整数作为起始值和停止值的切片表示法
使用整数使用 .iloc 选择单行
df.iloc[4]
这将返回第五行(整数位置为4)作为一系列数据
age 32
color gray
food Cheese
height 180
score 1.8
state AK
Name: Dean, dtype: object
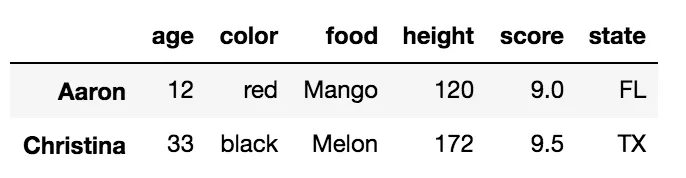
使用整数列表和 .iloc 选择多行
df.iloc[[2, -2]]
这将返回第三行和倒数第二行的DataFrame:
使用切片符号和.iloc选择多行
df.iloc[:5:3]

.loc和.iloc同时选择行和列
.loc/.iloc的一个优秀功能是它们能够同时选择行和列。在上面的示例中,每个选择都返回了所有列。我们可以像选择行一样选择列。只需要用逗号分隔行和列的选择。
例如,我们可以选择行Jane和Dean,并只选择高度、得分和州这几列:
df.loc[['Jane', 'Dean'], 'height':]
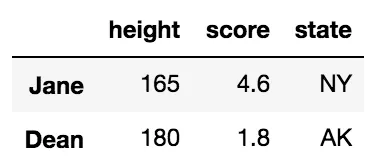
使用标签列表来表示行,使用切片符号来表示列。
我们可以使用整数在
.iloc中进行类似的操作。
df.iloc[[1,4], 2]
Nick Lamb
Dean Cheese
Name: food, dtype: object
使用标签和整数位置进行同时选择
.ix 曾经用于同时使用标签和整数位置进行选择,这非常有用但有时会让人感到困惑和模棱两可,幸运的是它已被弃用。如果您需要同时使用标签和整数位置进行选择,您将需要将两个选择都转换为标签或整数位置。
例如,如果我们想选择行 Nick 和 Cornelia 以及第2列和第4列,我们可以使用 .loc 通过以下方式将整数转换为标签:
col_names = df.columns[[2, 4]]
df.loc[['Nick', 'Cornelia'], col_names]
或者,使用get_loc索引方法将索引标签转换为整数。
labels = ['Nick', 'Cornelia']
index_ints = [df.index.get_loc(label) for label in labels]
df.iloc[index_ints, [2, 4]]
布尔选择
.loc索引器也可以进行布尔选择。例如,如果我们想要找到所有年龄超过30岁的行,并仅返回food和score列,我们可以执行以下操作:
df.loc[df['age'] > 30, ['food', 'score']]
您可以使用.iloc复制此操作,但无法将其传递给布尔序列。您必须像这样将布尔序列转换为numpy数组:
df.iloc[(df['age'] > 30).values, [2, 4]]
选择所有行
可以使用 .loc/.iloc 仅选择列。您可以通过使用冒号来选择所有行,如下所示:
df.loc[:, 'color':'score':2]
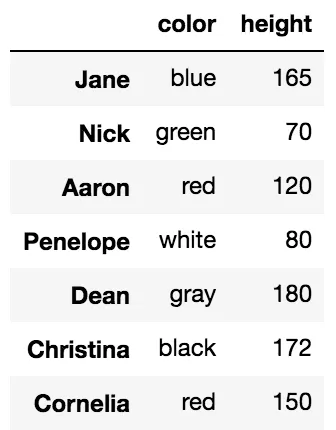
索引操作符[]可以切片选择行和列,但不能同时进行。
大多数人熟悉DataFrame索引运算符的主要用途,即选择列。字符串选择单个列作为Series,字符串列表选择多个列作为DataFrame。
df['food']
Jane Steak
Nick Lamb
Aaron Mango
Penelope Apple
Dean Cheese
Christina Melon
Cornelia Beans
Name: food, dtype: object
使用列表选择多个列
df[['food', 'score']]
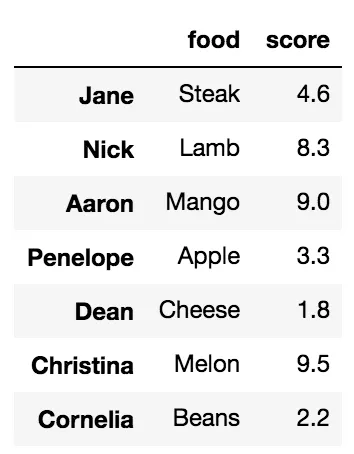
人们不太熟悉的是,当使用切片符号时,选择是按行标签或整数位置进行的。这非常令人困惑,我几乎从不使用它,但它确实有效。
df['Penelope':'Christina']
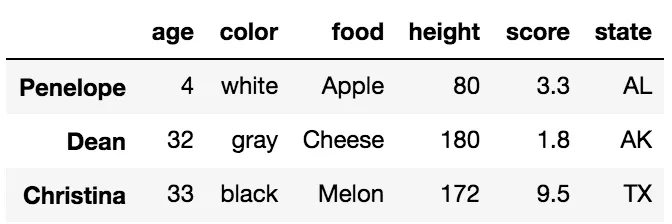
df[2:6:2]

.loc/.iloc 是选择行的明确方法,高度推荐使用。仅使用索引操作符无法同时选择行和列。
df[3:5, 'color']
TypeError: unhashable type: 'slice'
.at 和 .iat 进行选取
.at 的使用方法与 .loc 几乎相同,但它只选择 DataFrame 中的单个“单元格”。通常我们将此单元格称为标量值。要使用 .at,请传递行和列标签,用逗号隔开。
df.at['Christina', 'color']
'black'
使用
.iat进行选择与
.iloc几乎相同,但它仅选择单个标量值。您必须为行和列位置都传递整数。
df.iat[2, 5]
'FL'
loc是基于标签的索引,可以在行中查找值,iloc是基于整数位置的行索引,ix是一个通用方法,它首先执行基于标签的索引,如果失败,则使用基于整数位置的索引。建议不要使用已弃用的at方法。还有一件事需要考虑是你想做什么,因为其中一些方法允许切片和列赋值,老实说文档很清楚:http://pandas.pydata.org/pandas-docs/stable/indexing.html - EdChumat已经被弃用了?我在at(或者iat)文档中没有看到这个说明。 - Russloc、ix和iloc之间的区别:https://dev59.com/31wZ5IYBdhLWcg3wVO5U#31593712。 - Alex Riley