这里需要翻译的内容是:
我可以使用以下方法获取每列最小值的索引位置:
现在,我该如何找到列向最大值的最后一次出现位置,直到最小值的位置为止?
视觉上,我想找到下面绿色最大值的位置:
标题可能不太直观,让我举个例子。假设我有一个使用以下代码创建的df:
a = np.array([[ 1. , 0.9, 1. ],
[ 0.9, 0.9, 1. ],
[ 0.8, 1. , 0.5],
[ 1. , 0.3, 0.2],
[ 1. , 0.2, 0.1],
[ 0.9, 1. , 1. ],
[ 1. , 0.9, 1. ],
[ 0.6, 0.9, 0.7],
[ 1. , 0.9, 0.8],
[ 1. , 0.8, 0.9]])
idx = pd.date_range('2017', periods=a.shape[0])
df = pd.DataFrame(a, index=idx, columns=list('abc'))
我可以使用以下方法获取每列最小值的索引位置:
df.idxmin()
现在,我该如何找到列向最大值的最后一次出现位置,直到最小值的位置为止?
视觉上,我想找到下面绿色最大值的位置:
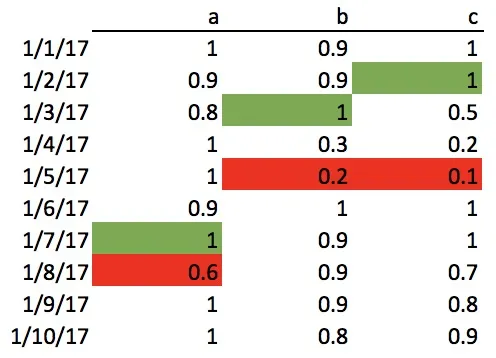
忽略最小出现后的最大值。
我可以使用.apply来完成这个任务,但是能否使用掩码/高级索引来完成?
期望结果:
a 2017-01-07
b 2017-01-03
c 2017-01-02
dtype: datetime64[ns]