简述
如果输入是NumPy数组,请参见这里。
如果输入是一个序列:
min()和max()通常比手动循环更快(除非使用key参数,然后取决于函数调用的速度)- 使用Python可以使手动循环更快,性能超过两个单独调用
min()和max()。
如果输入是非序列可迭代对象:
min()和max()不能在同一个可迭代对象上使用
- 需要将可迭代对象转换为
list()或tuple()(或者可以使用itertools.tee(),但是根据其文档,在这种情况下list()/tuple()转换更快),但具有较大的内存占用
- 可以使用单个循环方法,该方法可以再次通过Cython加速。
这里没有详细讨论显式key的情况,但下面报告了一种可以进行Cython适应的高效方法之一:
def extrema_for_with_key(items, key=None):
items = iter(items)
if callable(key):
try:
max_item = min_item = next(items)
max_val = min_val = key(item)
except StopIteration:
return None, None
else:
for item in items:
val = key(item)
if val > max_val:
max_val = val
max_item = item
elif val < min_val:
min_val = val
min_item = item
return max_item, min_item
else:
try:
max_item = min_item = next(items)
except StopIteration:
return None, None
else:
for item in items:
if item > max_item:
max_item = item
elif item < min_item:
min_item = item
return max_item, min_item
完整的基准测试
在这里。
更长的答案
虽然在纯Python中循环可能成为瓶颈,但是寻找最大值和最小值的问题可以用比两次单独调用max()和min()更少的步骤(比较和赋值)来解决——在随机分布的值序列上,更具体地说,只需遍历一次该序列(或可迭代对象)即可。
当使用key参数提供的功能时,或者当输入是一个迭代器并且将其转换为tuple()或list()(或使用itertools.tee())会导致过多的内存消耗时,这可能是有用的。
此外,如果可以通过Cython或Numba加速循环,则这种方法可能会导致更快的执行。
如果输入不是NumPy数组,则Cython的加速效果最佳,而如果输入是NumPy数组,则Numba的加速效果最大。
通常,将通用输入转换为NumPy数组的成本不会抵消使用Numba的速度增益。
有关NumPy数组的情况的讨论可以在此处找到。
基本实现,忽略`key`参数,如下(其中`min_loops()`和`max_loops()`本质上是使用循环重新实现的`min()`和`max()`):
def min_loops(seq):
iseq = iter(seq)
try:
result = next(iseq)
except StopIteration:
return None
else:
for item in iseq:
if item < result:
result = item
return result
def max_loops(seq):
iseq = iter(seq)
try:
result = next(iseq)
except StopIteration:
return None
else:
for item in iseq:
if item > result:
result = item
return result
def extrema_loops(items):
seq = tuple(items)
return max_loops(seq), min_loops(seq)
这些可以天真地组合成一个单循环,类似于 OP 的建议:
def extrema_for(seq):
iseq = iter(seq)
try:
max_val = min_val = next(iseq)
except StopIteration:
return None, None
else:
for item in iseq:
if item > max_val:
max_val = item
elif item < min_val:
min_val = item
return max_val, min_val
“elif”的使用可以有效地减少比较和赋值的数量(对于具有随机分布值的输入,“平均”每个元素约为1.5次)。通过同时考虑两个元素(在这两种情况下,“平均”每个元素的比较次数都为1.5),可以进一步减少赋值的数量。”
def extrema_for2(seq):
iseq = iter(seq)
try:
max_val = min_val = next(iseq)
except StopIteration:
return None, None
else:
for x, y in zip(iseq, iseq):
if x > y:
x, y = y, x
if x < min_val:
min_val = x
if y > max_val:
max_val = y
try:
last = next(iseq)
except StopIteration:
pass
else:
if last < min_val:
min_val = x
if last > max_val:
max_val = y
return max_val, min_val
每种方法的相对速度在很大程度上取决于每个指令的相对速度,而
extrema_for2()的替代实现可能会更快。例如,如果将主循环(
for x,y in zip(iseq,iseq))替换为
while True:x = next(iseq); y = next(iseq)结构,即:
def extrema_while(seq):
iseq = iter(seq)
try:
max_val = min_val = x = next(iseq)
try:
while True:
x = next(iseq)
y = next(iseq)
if x > y:
x, y = y, x
if x < min_val:
min_val = x
if y > max_val:
max_val = y
except StopIteration:
if x < min_val:
min_val = x
if x > max_val:
max_val = x
return max_val, min_val
except StopIteration:
return None, None
这在Python中实现起来较慢,
但是使用Cython加速后会更快。
这些以及以下的实现作为基准:
def extrema(seq):
return max(seq), min(seq)
def extrema_iter(items):
seq = tuple(items)
return max(seq), min(seq)
下面进行比较:
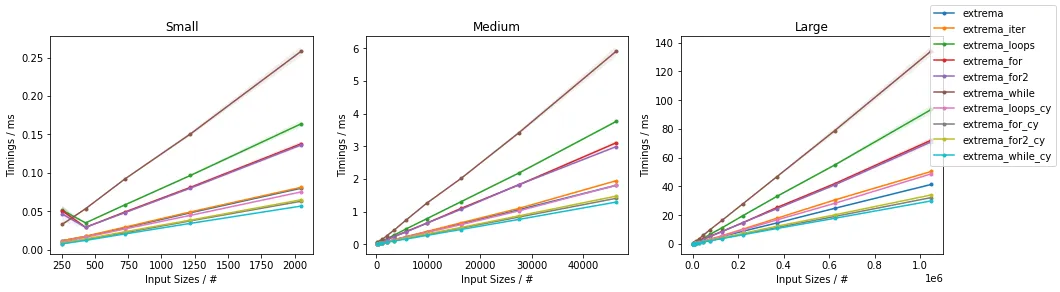
请注意一般情况下:
extrema_while() > extrema_loops() > extrema_for() > extrema_for2()(这是由于对next()的昂贵调用)extrema_loops_cy() > extrema_for_cy() > extrema_for2_cy() > extrema_while_cy()extrema_loops_cy()实际上比extrema()更慢。
函数有Cython对应项(带有_cy后缀),除了使用cpdef替换def外,本质上是相同的代码,例如:
%%cython -c-O3 -c-march=native -a
cpdef extrema_while_cy(seq):
items = iter(seq)
try:
max_val = min_val = x = next(items)
try:
while True:
x = next(items)
y = next(items)
if x > y:
x, y = y, x
if x < min_val:
min_val = x
if y > max_val:
max_val = y
except StopIteration:
if x < min_val:
min_val = x
if x > max_val:
max_val = x
return max_val, min_val
except StopIteration:
return None, None
完整基准测试
在此处。
iterable至少有一个键。否则,这将在min_ = max_...调用时失败。 - Ian Clarkelif呢? - Ian Clarkiterable[0]和iterable[1:]取消了这种优势。 - user2357112