set.seed(1)
n <- 400
x <- 0:(n-1)/(n-1)
f <- 0.2*x^11*(10*(1-x))^6+10*(10*x)^3*(1-x)^10
y <- f + rnorm(n, 0, sd = 2)
require(splines)
如果你想要普通最小二乘估计,你可以在公式中使用bs()函数作为lm。 bs函数提供由节点、多项式次数等确定的基础函数。
mod <- lm(y ~ bs(x, knots = seq(0.1, 0.9, by = 0.1)))
你可以像处理线性模型一样处理它。
> anova(mod)
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
bs(x, knots = seq(0.1, 0.9, by = 0.1)) 12 2997.5 249.792 65.477 < 2.2e-16 ***
Residuals 387 1476.4 3.815
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
关于结点位置的一些指针。 bs有一个参数Boundary.knots,默认为Boundary.knots = range(x) - 因此当我在上面指定knots参数时,我没有包括边界结点。
阅读?bs获取更多信息。
生成拟合样条的图形
在评论中,我讨论了如何绘制拟合的样条。一种选择是按照协变量的顺序对数据进行排序。这对单个协变量可以正常工作,但对于2个或更多的协变量可能不起作用。另一个问题是您只能评估观察值的x上的拟合样条 - 如果您没有密集采样协变量,则这是可以接受的,但如果没有,样条可能看起来很奇怪,具有长线性部分。
更通用的解决方案是使用predict为协变量的新值生成模型预测。在下面的代码中,我展示了如何为x范围内100个均匀间隔的值进行预测,以对上述模型进行预测。
pdat <- data.frame(x = seq(min(x), max(x), length = 100))
pdat <- transform(pdat, yhat = predict(mod, newdata = pdat))
ylim <- range(pdat$y, y)
plot(y ~ x)
lines(yhat ~ x, data = pdat, lwd = 2, col = "red")
那会产生:
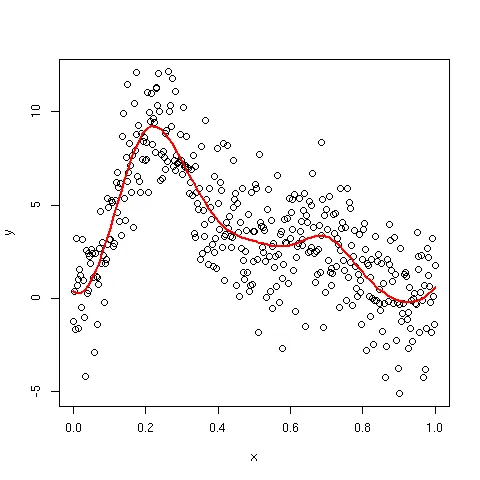
bs的功能,不是吗?默认情况下,在结点上用三次立方多项式拟合,并确保各个片段在结点处平滑连接。 - Gavin Simpsonlm(weight ~ bs(height, df = 3, knots=c(58, 62, 66, 70, 72), ), data = women)。 - IRTFM