让我们将@Daniel建议的内容转化为代码。
第一步
让我们导入multivariate_normal:
import numpy as np
from scipy.stats import multivariate_normal as mvn
步骤2
让我们构建协方差数据并生成数据:
cov = np.array([[1, 0.8,.7, .6],[.8,1.,.5,.5],[0.7,.5,1.,.5],[0.6,.5,.5,1]])
cov
array([[ 1. , 0.8, 0.7, 0.6],
[ 0.8, 1. , 0.5, 0.5],
[ 0.7, 0.5, 1. , 0.5],
[ 0.6, 0.5, 0.5, 1. ]])
这是关键的一步。请注意,协方差矩阵对角线上的数为1,从左到右的协方差逐渐减小。
现在我们已经准备好生成数据了,让我们生成1,000个点:
scores = mvn.rvs(mean = [60.,60.,60.,60.], cov=cov, size = 1000)
健康检查(从协方差矩阵到简单相关性):
np.corrcoef(scores.T):
array([[ 1. , 0.78886583, 0.70198586, 0.56810058],
[ 0.78886583, 1. , 0.49187904, 0.45994833],
[ 0.70198586, 0.49187904, 1. , 0.4755558 ],
[ 0.56810058, 0.45994833, 0.4755558 , 1. ]])
请注意,np.corrcoef希望您的数据按行排列。
最后,让我们将您的数据放入Pandas的DataFrame中:
df = pd.DataFrame(data = scores, columns = ["Math", "Science","History", "Art"])
df.head()
Math Science History Art
0 60.629673 61.238697 61.805788 61.848049
1 59.728172 60.095608 61.139197 61.610891
2 61.205913 60.812307 60.822623 59.497453
3 60.581532 62.163044 59.277956 60.992206
4 61.408262 59.894078 61.154003 61.730079
步骤三
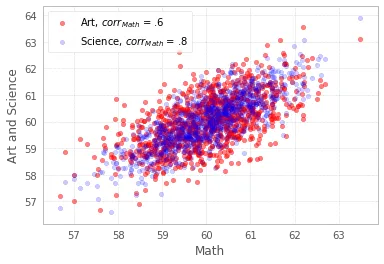
让我们来可视化一些刚刚生成的数据:
ax = df.plot(x = "Math",y="Art", kind="scatter", color = "r", alpha = .5, label = "Art, $corr_{Math}$ = .6")
df.plot(x = "Math",y="Science", kind="scatter", ax = ax, color = "b", alpha = .2, label = "Science, $corr_{Math}$ = .8")
ax.set_ylabel("Art and Science");
{kind=link}
scipy.stats.multivariate_normal.rvs()函数以该分布生成随机数据。 - Daniel F