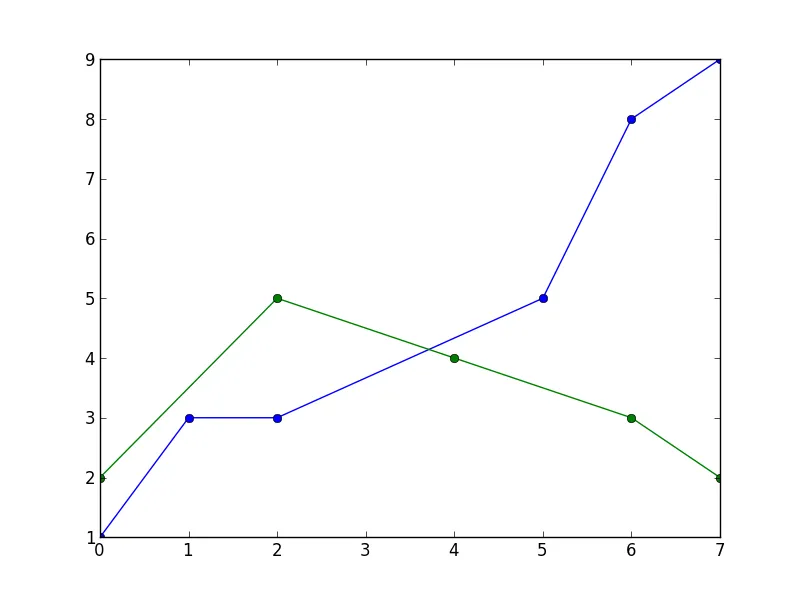
我曾经遇到同样的问题,但是使用遮罩消除了点之间的问题,而线条则会被切断(在图片中看到的粉色线条是唯一连续不为NaN的数据,因此形成了这条线)。以下是应用遮罩后的数据结果(仍然存在间隙):
xs = df['time'].to_numpy()
series1 = np.array(df['zz'].to_numpy()).astype(np.double)
s1mask = np.isfinite(series1)
fplt.plot(xs[s1mask], series1[s1mask], ax=ax_candle, color='#FF00FF', width = 1, legend='ZZ')
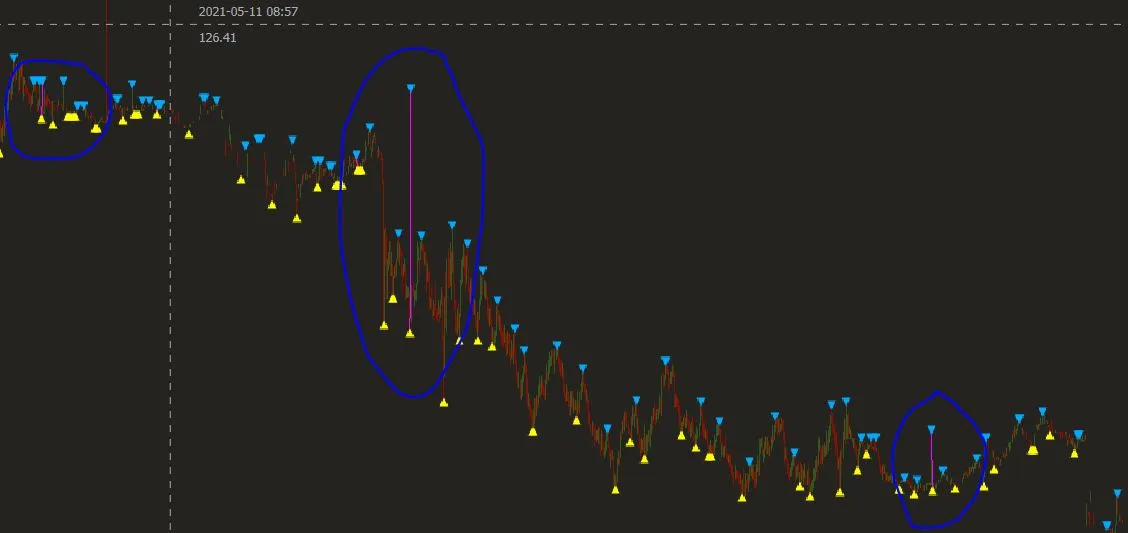
也许是因为我使用了finplot(绘制蜡烛图),所以我决定使用线性公式y2-y1=m(x2-x1)来补充缺失的Y轴点,然后制定生成缺失点之间Y值的函数。
def fillYLine(y):
fi=0
first = None
next = None
for i in range(0,len(y),1):
ne = not(isnan(y[i]))
next = y[i] if ne else next
if not(next is None):
if not(first is None):
m = (first-next)/(i-fi)
cant_points = np.abs(i-fi)-1
if (cant_points)>0:
points = createLine(next,first,i,fi,cant_points)
x = 1
for p in points:
y[fi+x] = p
x = x + 1
first = next
fi = i
next = None
return y
def createLine(y2,y1,x2,x1,cant_points):
m = (y2-y1)/(x2-x1)
points = []
x = x1 + 1
for i in range(0,cant_points,1):
y = ((m*(x2-x))-y2)*-1
points.append(y)
x = x + 1
return points
然后我使用简单的函数调用来填补它们之间的空隙,比如 y = fillYLine(y),我的 finplot 就像这样:
x = df['time'].to_numpy()
y = df['zz'].to_numpy()
y = fillYLine(y)
fplt.plot(x, y, ax=ax_candle, color='#FF00FF', width = 1, legend='ZZ')
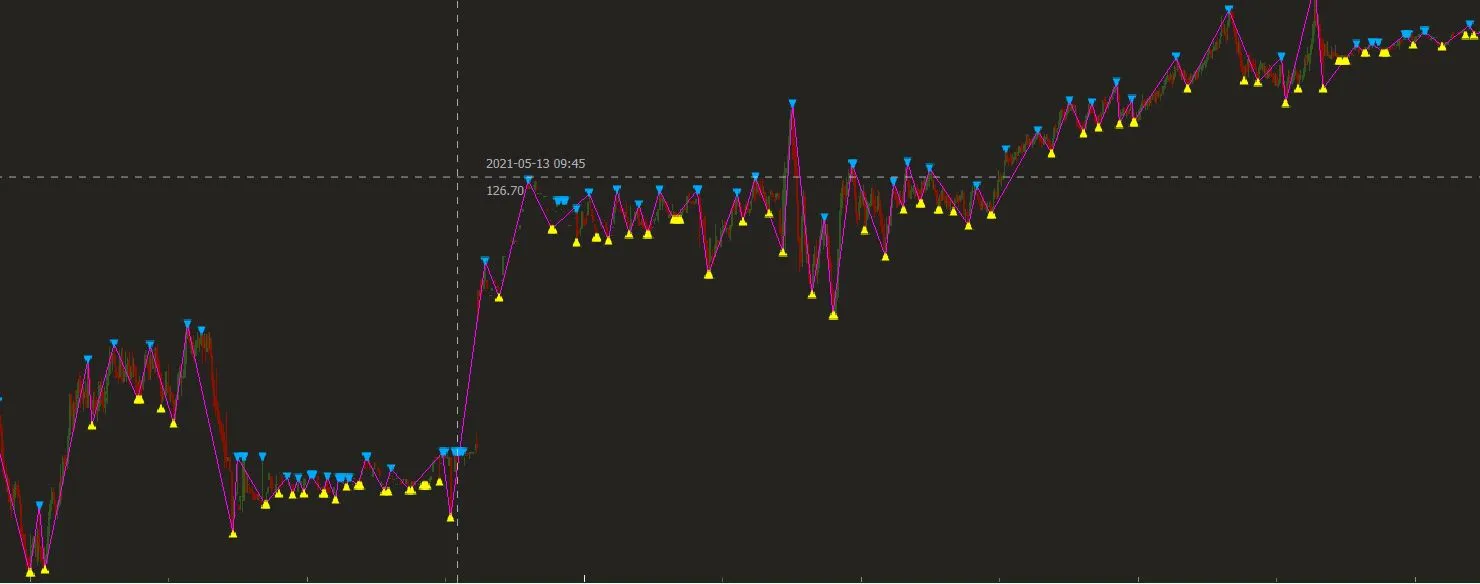
您需要注意的是,Y变量中的数据仅用于绘图,我需要在操作过程中保留NaN值(或从列表中删除它们),这就是为什么我从pandas数据集
df ['zz']创建了一个Y变量的原因。
注意:我注意到数据被消除是因为如果我不掩盖X(xs),值会向左滑动在图表中,此时它们变成连续的非NaN值并且绘制连续线但向左缩小:
fplt.plot(xs, series1[s1mask], ax=ax_candle, color='#FF00FF', width = 1, legend='ZZ') #No xs masking (xs[masking])
这让我想到,一些人戴口罩的原因是因为他们只在意那条线或者非戴口罩数据和戴口罩数据之间没有太大差异(缺口很少,不像我的数据有很多)。