原问题
我想要平滑我的自变量,例如一辆车的速度数据,然后使用这些平滑值。我搜索了很多资料,但没有找到直接回答我的答案。
我知道如何计算核密度估计 (density() 或 KernSmooth::bkde()),但是我不知道如何计算速度的平滑值。
重新编辑的问题
感谢@ZheyuanLi,我能更好地解释我拥有的内容以及我想要做什么。因此,我已经重新编辑了我的问题,如下:
我有一些车辆在某段时间内的速度测量值,存储为数据帧vehicle:
t speed
1 0 0.0000000
2 1 0.0000000
3 2 0.0000000
4 3 0.0000000
5 4 0.0000000
. . .
. . .
1031 1030 4.8772222
1032 1031 4.4525000
1033 1032 3.2261111
1034 1033 1.8011111
1035 1034 0.2997222
1036 1035 0.2997222
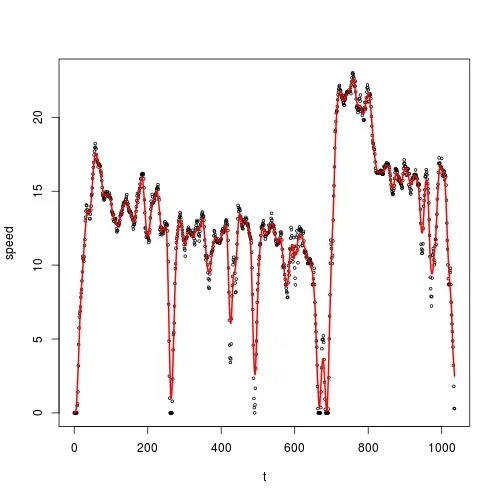
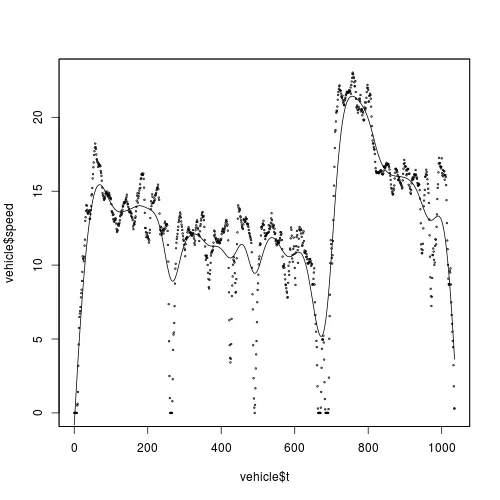
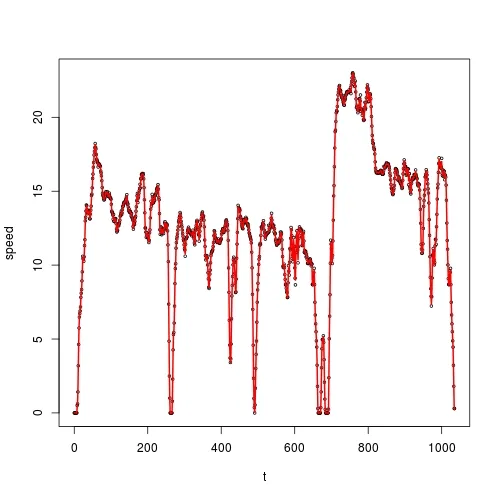
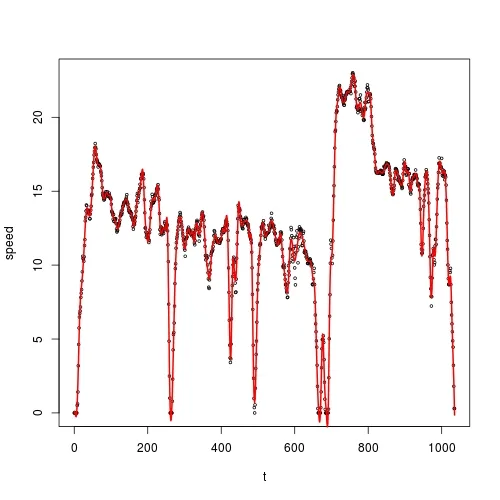
这里是一个散点图:
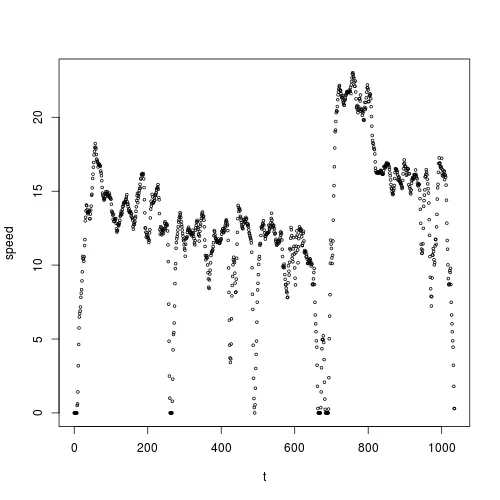
我想要对 t 上的 speed 进行平滑,并且我想要使用核平滑法。根据 @Zheyuan 的建议,我应该使用 ksmooth():
fit <- ksmooth(vehicle$t, vehicle$speed)
然而,我发现平滑后的数值与我的原始数据完全相同:
sum(abs(fit$y - vehicle$speed)) # 0
为什么会发生这种情况?谢谢!
density函数。 您可以将其分配为Y<-density(Speed)并获取Y$y,这是平滑值。 - akash87loess函数通常用于非参数平滑。它具有一个预测方法。对于平滑计算 kde 没有太多意义,也许您应该发布一个例子。从未排序的值开始,对其进行排序并估计它们的局部“接近度”。 - IRTFM