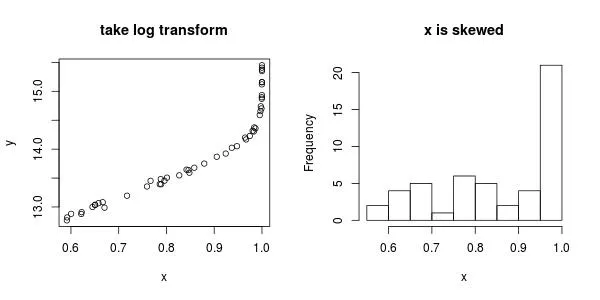
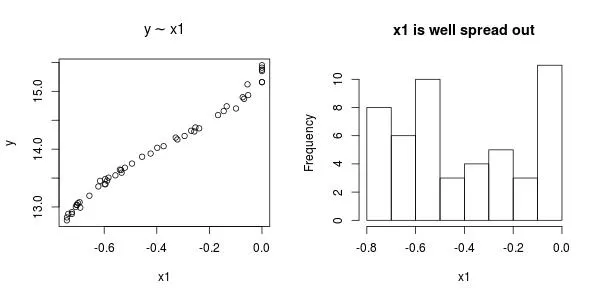
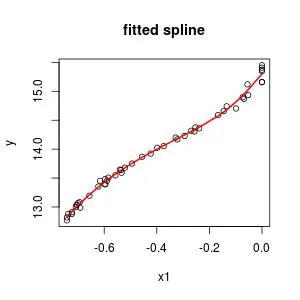
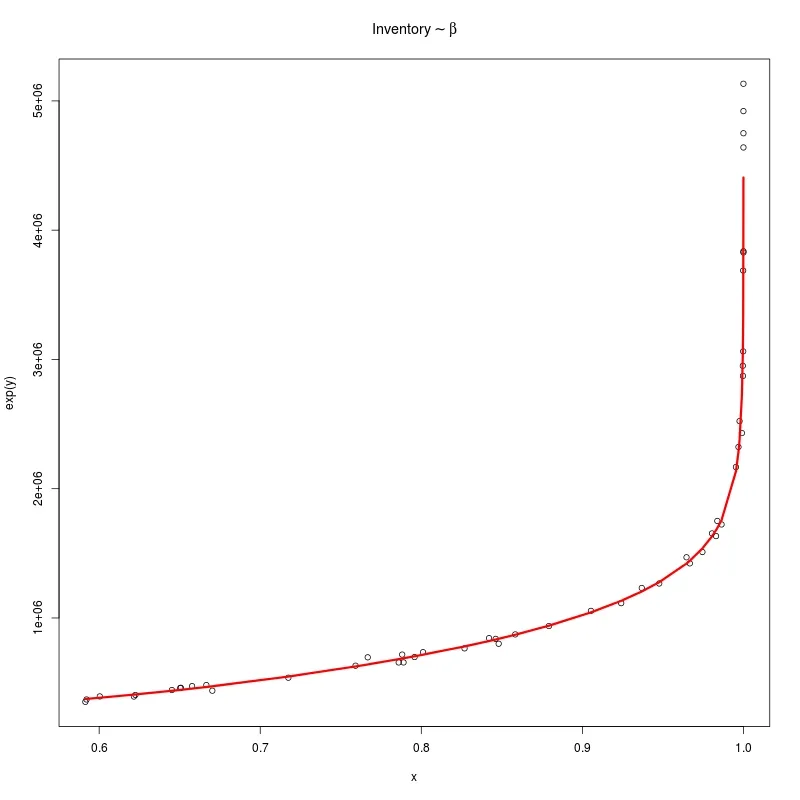
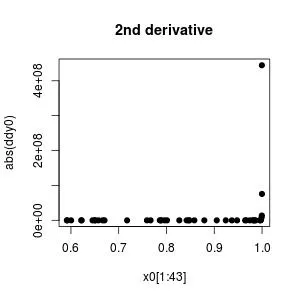
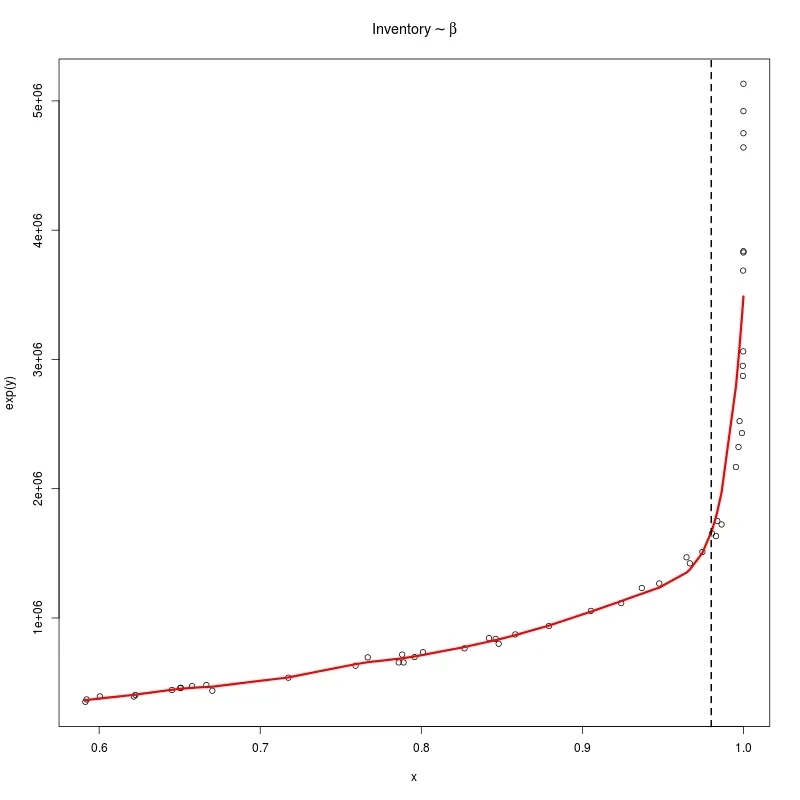
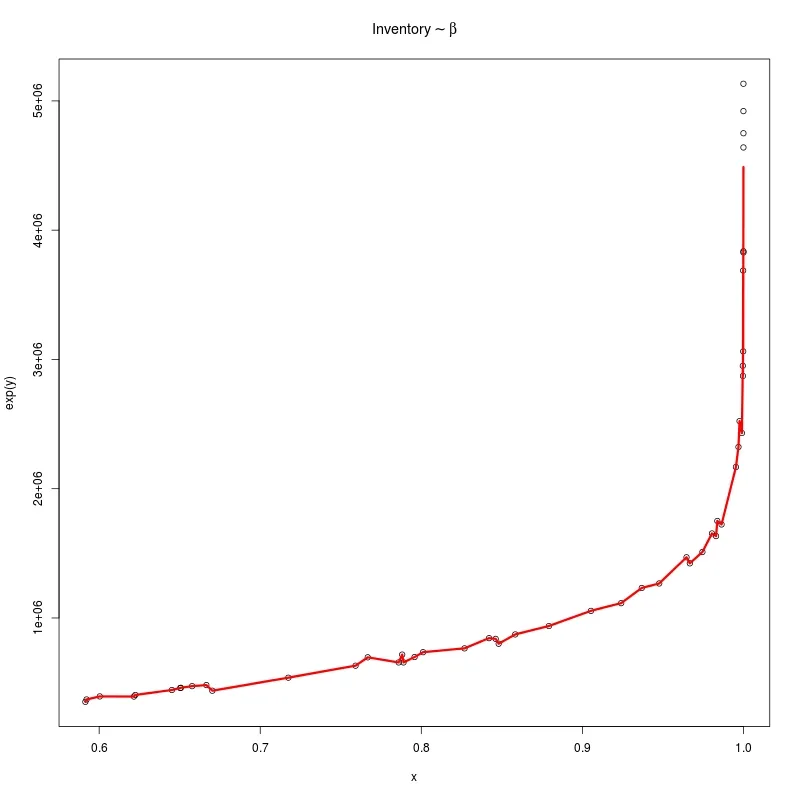
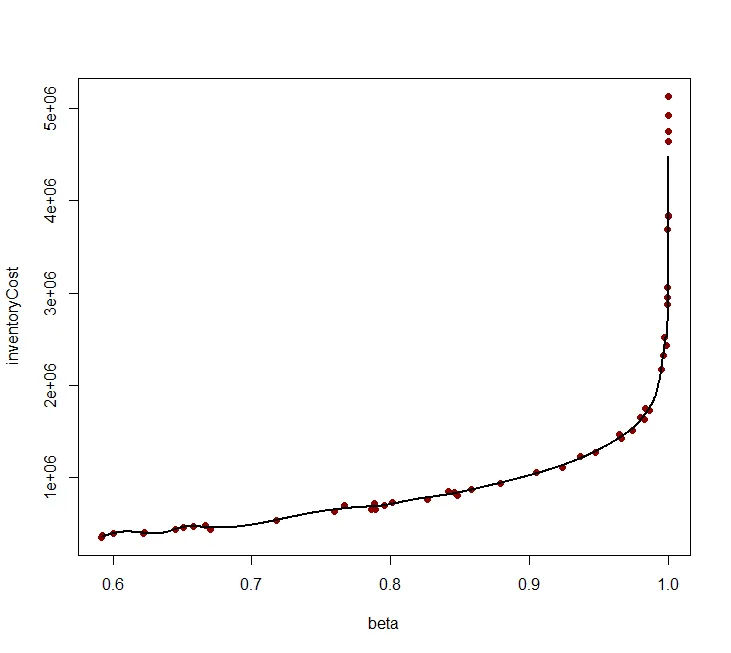
我有几个数据点,似乎适合通过它们拟合样条曲线。但是当我这样做时,我得到了一个相当崎岖的拟合,就像过度拟合一样,这不是我理解的平滑处理。
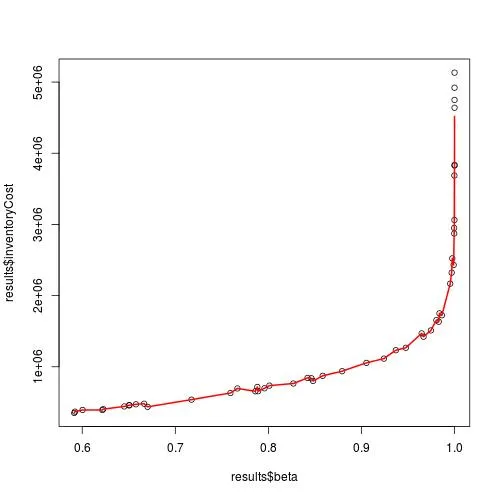
是否有特殊选项/参数可以获得真正平滑的样条曲线函数呢? 像此处一样。
对于smooth.spline 的penalty 参数的使用似乎没有任何可见影响。也许我做错了吗?
以下是数据和代码:
results <- structure(
list(
beta = c(
0.983790622281964, 0.645152464354322,
0.924104713597375, 0.657703886566088, 0.788138034115623, 0.801080207252363,
1, 0.858337365965949, 0.999687052533693, 0.666552625121279, 0.717453633245958,
0.621570152961453, 0.964658181346544, 0.65071758770312, 0.788971505000918,
0.980476054183113, 0.670263506919246, 0.600387040967624, 0.759173403408052,
1, 0.986409675965, 0.982996471134736, 1, 0.995340781899163, 0.999855895958986,
1, 0.846179233381267, 0.879226324448832, 0.795820998892035, 0.997586607285667,
0.848036806290156, 0.905320944437968, 0.947709125535428, 0.592172373022407,
0.826847031044922, 0.996916006944244, 0.785967729206612, 0.650346929853076,
0.84206351833549, 0.999043126652724, 0.936879214753098, 0.76674066557003,
0.591431233516217, 1, 0.999833445117791, 0.999606223666537, 0.6224971799303,
1, 0.974537160571494, 0.966717133936379
), inventoryCost = c(
1750702.95138889,
442784.114583333, 1114717.44791667, 472669.357638889, 716895.920138889,
735396.180555556, 3837320.74652778, 872873.4375, 2872414.93055556,
481095.138888889, 538125.520833333, 392199.045138889, 1469500.95486111,
459873.784722222, 656220.486111111, 1654143.83680556, 437511.458333333,
393295.659722222, 630952.170138889, 4920958.85416667, 1723517.10069444,
1633579.86111111, 4639909.89583333, 2167748.35069444, 3062420.65972222,
5132702.34375, 838441.145833333, 937659.288194444, 697767.1875,
2523016.31944444, 800903.819444444, 1054991.49305556, 1266970.92013889,
369537.673611111, 764995.399305556, 2322879.6875, 656021.701388889,
458403.038194444, 844133.420138889, 2430700, 1232256.68402778,
695574.479166667, 351348.524305556, 3827440.71180556, 3687610.41666667,
2950652.51736111, 404550.78125, 4749901.64930556, 1510481.59722222,
1422708.07291667
)
), .Names = c("beta", "inventoryCost"), class = c("data.frame")
)
plot(results$beta,results$inventoryCost)
mySpline <- smooth.spline(results$beta,results$inventoryCost, penalty=999999)
lines(mySpline$x, mySpline$y, col="red", lwd = 2)