这个问题与我之前提出的这个问题有关。但是,回答这个问题不需要参考那个问题。
数据
我有一个包含2169辆车速度的数据集,记录间隔为0.1秒。因此,对于每辆车,会有很多行数据。在这里,我仅重现了车辆#2的数据:
> dput(uma)
structure(list(Frame.ID = 13:445, Vehicle.velocity = c(40, 40,
40, 40, 40, 40, 40, 40.02, 40.03, 39.93, 39.61, 39.14, 38.61,
38.28, 38.42, 38.78, 38.92, 38.54, 37.51, 36.34, 35.5, 35.08,
34.96, 34.98, 35, 34.99, 34.98, 35.1, 35.49, 36.2, 37.15, 38.12,
38.76, 38.95, 38.95, 38.99, 39.18, 39.34, 39.2, 38.89, 38.73,
38.88, 39.28, 39.68, 39.94, 40.02, 40, 39.99, 39.99, 39.65, 38.92,
38.52, 38.8, 39.72, 40.76, 41.07, 40.8, 40.59, 40.75, 41.38,
42.37, 43.37, 44.06, 44.29, 44.13, 43.9, 43.92, 44.21, 44.59,
44.87, 44.99, 45.01, 45.01, 45, 45, 45, 44.79, 44.32, 43.98,
43.97, 44.29, 44.76, 45.06, 45.36, 45.92, 46.6, 47.05, 47.05,
46.6, 45.92, 45.36, 45.06, 44.96, 44.97, 44.99, 44.99, 44.99,
44.99, 45.01, 45.02, 44.9, 44.46, 43.62, 42.47, 41.41, 40.72,
40.49, 40.6, 40.76, 40.72, 40.5, 40.38, 40.43, 40.38, 39.83,
38.59, 37.02, 35.73, 35.04, 34.85, 34.91, 34.99, 34.99, 34.97,
34.96, 34.98, 35.07, 35.29, 35.54, 35.67, 35.63, 35.53, 35.53,
35.63, 35.68, 35.55, 35.28, 35.06, 35.09, 35.49, 36.22, 37.08,
37.8, 38.3, 38.73, 39.18, 39.62, 39.83, 39.73, 39.58, 39.57,
39.71, 39.91, 40, 39.98, 39.97, 40.08, 40.38, 40.81, 41.27, 41.69,
42.2, 42.92, 43.77, 44.49, 44.9, 45.03, 45.01, 45, 45, 45, 45,
45, 45, 45, 45, 45, 45, 45, 44.99, 45.03, 45.26, 45.83, 46.83,
48.2, 49.68, 50.95, 51.83, 52.19, 52, 51.35, 50.38, 49.38, 48.63,
48.15, 47.87, 47.78, 48.01, 48.63, 49.52, 50.39, 50.9, 50.96,
50.68, 50.3, 50.05, 49.94, 49.87, 49.82, 49.82, 49.88, 49.96,
50, 50, 49.98, 49.98, 50.16, 50.64, 51.43, 52.33, 53.01, 53.27,
53.22, 53.25, 53.75, 54.86, 56.36, 57.64, 58.28, 58.29, 57.94,
57.51, 57.07, 56.64, 56.43, 56.73, 57.5, 58.27, 58.55, 58.32,
57.99, 57.89, 57.92, 57.74, 57.12, 56.24, 55.51, 55.1, 54.97,
54.98, 55.02, 55.03, 54.86, 54.3, 53.25, 51.8, 50.36, 49.41,
49.06, 49.17, 49.4, 49.51, 49.52, 49.51, 49.45, 49.24, 48.84,
48.29, 47.74, 47.33, 47.12, 47.06, 47.07, 47.08, 47.05, 47.04,
47.25, 47.68, 47.93, 47.56, 46.31, 44.43, 42.7, 41.56, 41.03,
40.92, 40.92, 40.98, 41.19, 41.45, 41.54, 41.32, 40.85, 40.37,
40.09, 39.99, 39.99, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40,
39.98, 39.97, 40.1, 40.53, 41.36, 42.52, 43.71, 44.57, 45.01,
45.1, 45.04, 45, 45, 45, 45, 45, 45, 44.98, 44.97, 45.08, 45.39,
45.85, 46.2, 46.28, 46.21, 46.29, 46.74, 47.49, 48.35, 49.11,
49.63, 49.89, 49.94, 49.97, 50.14, 50.44, 50.78, 51.03, 51.12,
51.05, 50.85, 50.56, 50.26, 50.06, 50.1, 50.52, 51.36, 52.5,
53.63, 54.46, 54.9, 55.03, 55.09, 55.23, 55.35, 55.35, 55.23,
55.07, 54.99, 54.98, 54.97, 55.06, 55.37, 55.91, 56.66, 57.42,
58.07, 58.7, 59.24, 59.67, 59.95, 60.02, 60, 60, 60, 60, 60,
60.01, 60.06, 60.23, 60.65, 61.34, 62.17, 62.93, 63.53, 64, 64.41,
64.75, 65.04, 65.3, 65.57, 65.75, 65.74, 65.66, 65.62, 65.71,
65.91, 66.1, 66.26, 66.44, 66.61, 66.78, 66.91, 66.99, 66.91,
66.7, 66.56, 66.6, 66.83, 67.17, 67.45, 67.75, 68.15, 68.64,
69.15, 69.57, 69.79, 69.79, 69.72, 69.72, 69.81, 69.94, 70, 70.01,
70.02, 70.03)), .Names = c("Frame.ID", "Vehicle.velocity"), class = "data.frame", row.names = c(NA,
433L))
Frame.ID 是观测到 Vehicle.velocity 的时间帧。由于速度变量存在一些噪音,我想要对其进行平滑处理。
方法
我使用以下方程来平滑速度:
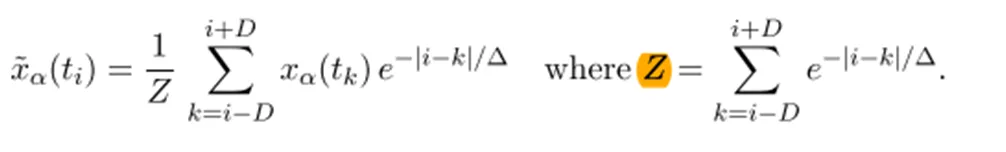
其中,
Delta = 10
Nalpha = 数据点数(行数)
i = 1, ... ,Nalpha(即行号)
D = {i-1, Nalpha - i, 3*delta=30} 中的最小值
xalpha = 速度
问题
我已经查阅了 R 中 filter 和 convolution 的文档。看起来我需要了解卷积才能完成这个任务。然而,我已经尽力了,但仍然不理解卷积是如何工作的!链接中的答案帮助我了解了一些函数内部的工作原理,但我还是不确定。
请问有谁能在 SO 上解释一下这个东西是如何工作的吗?或者指导我使用其他方法来实现同样的目的,即应用该方程?
我的当前代码很冗长,但可行
下面是 uma 的代码:
> head(uma)
Frame.ID Vehicle.velocity
1 13 40
2 14 40
3 15 40
4 16 40
5 17 40
6 18 40
uma$i <- 1:nrow(uma) # this is i
uma$im1 <- uma$i - 1
uma$Nai <- nrow(uma) - uma$i # this is Nalpha
uma$delta3 <- 30 # this is 3 times delta
uma$D <- pmin(uma$im1, uma$Nai, uma$delta3) # selecting the minimum of {i-1, Nalpha - i, 3*delta=15}
uma$imD <- uma$i - uma$D # i-D
uma$ipD <- uma$i + uma$D # i+D
uma <- ddply(uma, .(Frame.ID), transform, k = imD:ipD) # to include all k in the data frame
umai <- uma
umai$imk <- umai$i - umai$k # i-k
umai$aimk <- (-1) * abs(umai$imk) # -|i-k|
umai$delta <- 10
umai$kernel <- exp(umai$aimk/umai$delta) # The kernel in the equation i.e. EXP^-|i-k|/delta
umai$p <- umai$Vehicle.velocity[match(umai$k,umai$i)] #observed velocity in kth row as described in equation as t(k)
umai$kernelp <- umai$p * umai$kernel # the product of kernel and observed velocity in kth row as described in equation as t(k)
umair <- ddply(umai, .(Frame.ID), summarize, Z = sum(kernel), prod = sum(kernelp)) # summing the kernel to get Z and summing the product to get the numerator of the equation
umair$new.Y <- umair$prod/umair$Z # the final step to get the smoothed velocity
绘图
仅供参考,如果我将观测到的速度和平滑后的速度绘制成时间框架图,我们可以看到平滑的结果:
ggplot() +
geom_point(data=uma,aes(y=Vehicle.velocity, x= Frame.ID)) +
geom_point(data=umair,aes(y=new.Y, x= Frame.ID), color="red")
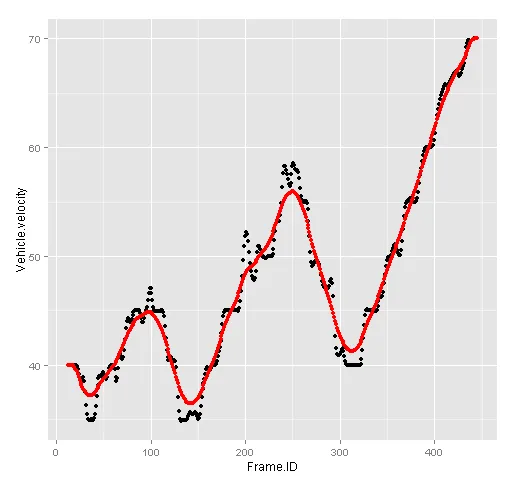
请帮助我通过指导卷积的使用,使我的代码变得简短并适用于所有车辆(由数据集中的Vehicle.ID表示)。
dplyr
好的,所以我使用了以下代码,它可以工作,但需要32 GB RAM 3小时。有人能建议如何加速它吗(每个小时都需要umal、umav和umaa花费1小时)?
uma <- tbl_df(uma)
uma <- uma %>% # take data frame
group_by(Vehicle.ID) %>% # group by Vehicle ID
mutate(i = 1:length(Frame.ID), im1 = i-1, Nai = length(Frame.ID) - i,
Dv = pmin(im1, Nai, 30),
Da = pmin(im1, Nai, 120),
Dl = pmin(im1, Nai, 15),
imDv = i - Dv,
ipDv = i + Dv,
imDa = i - Da,
ipDa = i + Da,
imDl = i - Dl,
ipDl = i + Dl) %>% # finding i, i-1 and Nalpha-i, D, i-D and i+D for location, velocity and acceleration
ungroup()
umav <- uma %>%
group_by(Vehicle.ID, Frame.ID) %>%
do(data.frame(kv = .$imDv:.$ipDv)) %>%
left_join(x=., y=uma) %>%
mutate(imk = i - kv, aimk = (-1) * abs(imk), delta = 10, kernel = exp(aimk/delta)) %>%
ungroup() %>%
group_by(Vehicle.ID) %>%
mutate(p = Vehicle.velocity2[match(kv,i)], kernelp = p * kernel) %>%
ungroup() %>%
group_by(Vehicle.ID, Frame.ID) %>%
summarise(Z = sum(kernel), prod = sum(kernelp)) %>%
mutate(svel = prod/Z) %>%
ungroup()
umaa <- uma %>%
group_by(Vehicle.ID, Frame.ID) %>%
do(data.frame(ka = .$imDa:.$ipDa)) %>%
left_join(x=., y=uma) %>%
mutate(imk = i - ka, aimk = (-1) * abs(imk), delta = 10, kernel = exp(aimk/delta)) %>%
ungroup() %>%
group_by(Vehicle.ID) %>%
mutate(p = Vehicle.acceleration2[match(ka,i)], kernelp = p * kernel) %>%
ungroup() %>%
group_by(Vehicle.ID, Frame.ID) %>%
summarise(Z = sum(kernel), prod = sum(kernelp)) %>%
mutate(sacc = prod/Z) %>%
ungroup()
umal <- uma %>%
group_by(Vehicle.ID, Frame.ID) %>%
do(data.frame(kl = .$imDl:.$ipDl)) %>%
left_join(x=., y=uma) %>%
mutate(imk = i - kl, aimk = (-1) * abs(imk), delta = 10, kernel = exp(aimk/delta)) %>%
ungroup() %>%
group_by(Vehicle.ID) %>%
mutate(p = Local.Y[match(kl,i)], kernelp = p * kernel) %>%
ungroup() %>%
group_by(Vehicle.ID, Frame.ID) %>%
summarise(Z = sum(kernel), prod = sum(kernelp)) %>%
mutate(ycoord = prod/Z) %>%
ungroup()
umal <- select(umal,c("Vehicle.ID", "Frame.ID", "ycoord"))
umav <- select(umav, c("Vehicle.ID", "Frame.ID", "svel"))
umaa <- select(umaa, c("Vehicle.ID", "Frame.ID", "sacc"))
umair <- left_join(uma, umal) %>% left_join(x=., y=umav) %>% left_join(x=., y=umaa)
transform的ddply已经运行了1个小时,但仍在运行中!我真的需要你的帮助。 - umair durraniddply执行时间过长时,通常的响应是切换到更高效的策略,例如使用 data.table 或 dplyr 包。 - IRTFM