其他答案都是很好的方法。然而,在R中还有一些其他选项没有被提到,包括lowess和approx,它们可能会给出更好的拟合或更快的性能。
这些优点可以更容易地通过替代数据集来演示:
sigmoid <- function(x)
{
y<-1/(1+exp(-.15*(x-100)))
return(y)
}
dat<-data.frame(x=rnorm(5000)*30+100)
dat$y<-as.numeric(as.logical(round(sigmoid(dat$x)+rnorm(5000)*.3,0)))
这是用Sigmoid曲线生成的数据叠加在一起的结果:
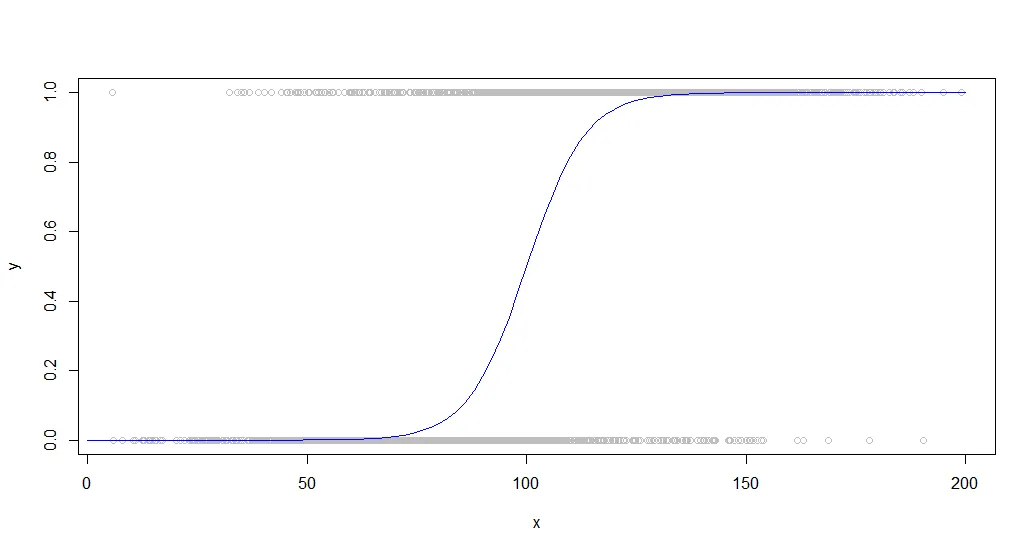
当我们观察人群中的二元行为时,这种数据很常见。例如,这可能是一个客户是否购买某物(y轴上的二元1/0)与他们在网站上花费的时间(x轴)的情况。
大量的点被用来更好地展示这些函数之间的性能差异。
在像这样的数据集上,Smooth、spline和smooth.spline使用任何我尝试过的参数都会产生无意义的结果,也许是因为它们倾向于映射到每个点,而嘈杂的数据不适合这种方法。
loess、lowess和approx函数都可以产生可用的结果,尽管对于approx来说勉强而已。下面是每个函数使用轻度优化参数的代码:
loessFit <- loess(y~x, dat, span = 0.6)
loessFit <- data.frame(x=loessFit$x,y=loessFit$fitted)
loessFit <- loessFit[order(loessFit$x),]
approxFit <- approx(dat,n = 15)
lowessFit <-data.frame(lowess(dat,f = .6,iter=1))
结果如下:
plot(dat,col='gray')
curve(sigmoid,0,200,add=TRUE,col='blue',)
lines(lowessFit,col='red')
lines(loessFit,col='green')
lines(approxFit,col='purple')
legend(150,.6,
legend=c("Sigmoid","Loess","Lowess",'Approx'),
lty=c(1,1),
lwd=c(2.5,2.5),col=c("blue","green","red","purple"))
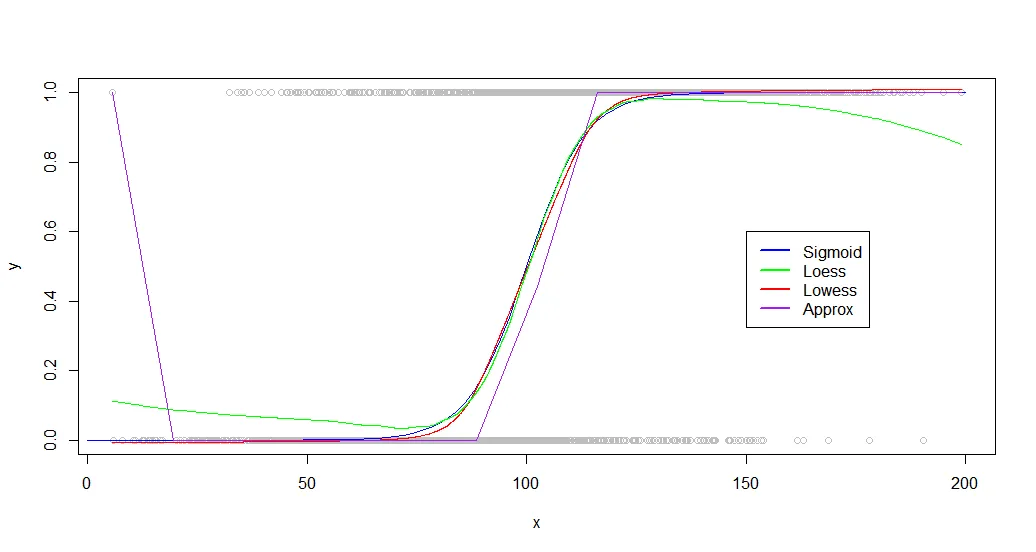
正如您所看到的,lowess 对原始生成曲线产生了近乎完美的拟合。Loess 接近,但在两端经历了奇怪的偏差。
尽管您的数据集将会非常不同,但我发现其他数据集表现类似,loess 和 lowess 都能够产生良好的结果。当您查看基准测试时,这些差异变得更加显著:
> microbenchmark::microbenchmark(loess(y~x, dat, span = 0.6),approx(dat,n = 20),lowess(dat,f = .6,iter=1),times=20)
Unit: milliseconds
expr min lq mean median uq max neval cld
loess(y ~ x, dat, span = 0.6) 153.034810 154.450750 156.794257 156.004357 159.23183 163.117746 20 c
approx(dat, n = 20) 1.297685 1.346773 1.689133 1.441823 1.86018 4.281735 20 a
lowess(dat, f = 0.6, iter = 1) 9.637583 10.085613 11.270911 11.350722 12.33046 12.495343 20 b
Loess非常缓慢,比approx慢100倍。 Lowess产生比approx更好的结果,而仍然运行相当快(比loess快15倍)。
Loess在点数增加时也变得越来越拖沓,在大约50,000个点左右变得无法使用。
编辑:进一步的研究表明,对于某些数据集,loess提供更好的适合度。如果您处理的是小型数据集或性能不是考虑因素,请尝试这两种函数并比较结果。

{kind=link}
{kind=link}