如何正确有效地实现__hash__()函数?
我所说的是返回哈希值的函数,该哈希值用于将对象插入哈希表(也称为字典)中。
__hash__()函数返回一个整数,并用于将对象“分配”到哈希表中。因此,我认为对于常见数据,返回整数的值应该是均匀分布的(以尽量减少碰撞)。那么如何获得这样的值呢?碰撞是否是一个问题?在我的案例中,我有一个小的类作为容器,其中包含了一些整数、一些浮点数和一个字符串。
如何正确有效地实现__hash__()函数?
我所说的是返回哈希值的函数,该哈希值用于将对象插入哈希表(也称为字典)中。
__hash__()函数返回一个整数,并用于将对象“分配”到哈希表中。因此,我认为对于常见数据,返回整数的值应该是均匀分布的(以尽量减少碰撞)。那么如何获得这样的值呢?碰撞是否是一个问题?在我的案例中,我有一个小的类作为容器,其中包含了一些整数、一些浮点数和一个字符串。
实现__hash__()方法的一种简单且正确的方式是使用键元组。虽然它不像专门的哈希算法那样快,但如果您需要这样的话,那么您可能应该在C中实现该类型。
以下是使用键进行哈希和相等性比较的示例:
class A:
def __key(self):
return (self.attr_a, self.attr_b, self.attr_c)
def __hash__(self):
return hash(self.__key())
def __eq__(self, other):
if isinstance(other, A):
return self.__key() == other.__key()
return NotImplemented
同时,__hash__方法的文档提供了更多信息,在特定情况下可能会很有价值。
John Millikin提出了类似于这个解决方案的策略:
class A(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
def __eq__(self, othr):
return (isinstance(othr, type(self))
and (self._a, self._b, self._c) ==
(othr._a, othr._b, othr._c))
def __hash__(self):
return hash((self._a, self._b, self._c))
hash(A(a, b, c)) == hash((a, b, c)),换句话说,哈希与其关键成员的元组相撞。也许在实践中这并不经常发生?更新:Python文档现在建议像上面的示例一样使用元组。请注意,文档说明如下:
请注意,反之不一定成立。不相等的对象可能具有相同的哈希值。这种哈希冲突不会导致一个对象替换另一个对象,当作为字典键或集合元素使用时,只要对象不相等即可。唯一需要满足的属性是对比相等的对象具有相同的哈希值
Python文档中的__hash__建议使用类似XOR的方法结合子组件的哈希值,给出了以下代码:
class B(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
def __eq__(self, othr):
if isinstance(othr, type(self)):
return ((self._a, self._b, self._c) ==
(othr._a, othr._b, othr._c))
return NotImplemented
def __hash__(self):
return (hash(self._a) ^ hash(self._b) ^ hash(self._c) ^
hash((self._a, self._b, self._c)))
更新:正如Blckknght所指出的那样,改变a、b和c的顺序可能会引起问题。我添加了一个额外的^ hash((self._a, self._b, self._c))来捕获哈希值的顺序。如果组合的值不能重新排列(例如,它们具有不同的类型,因此永远不会将_a的值分配给_b或_c等),则可以删除这个最终的^ hash(...)。
hash(A(1, 2, 3))将等于hash(A(3, 1, 2))(它们都将与任何具有“1”、“2”和“3”排列的其他“A”实例哈希相等)。如果您想避免实例具有与其参数元组相同的哈希值,则可以创建一个哨兵值(作为类变量或全局变量),然后将其包含在要进行哈希处理的元组中:return hash((_sentinel, self._a, self._b, self._c))。 - Blckknghtisinstance 可能会有问题,因为 type(self) 的子类对象现在可以等于 type(self) 的对象。所以,根据插入的顺序,将 Car 和 Ford 添加到 set() 中可能只会插入一个对象。此外,你可能会遇到这样一种情况:a == b 为 True,但 b == a 为 False。 - MaratCB,你可能想将其更改为 isinstance(othr, B)。 - millerdevhash((type(self), self._a, self._b, self._c))。 - Ben MosherB 而不是 type(self) 的观点之外,通常认为在 __eq__ 中遇到意外类型时返回 NotImplemented 而不是 False 是更好的实践。这允许其他用户定义的类型实现一个知道 B 并且可以与其相等比较的 __eq__,如果他们愿意的话。 - Mark Amery微软研究员Paul Larson研究了多种哈希函数。他告诉我,
for c in some_string:
hash = 101 * hash + ord(c)
这种方法在处理各种不同的字符串时效果令人惊讶地好。我发现类似的多项式技术在计算不同子字段的哈希值时也非常有效。
__hash__方法;我们不需要自己创建。问题是如何为典型的用户定义类(其中有许多属性指向内置类型或其他类似的用户定义类)实现__hash__,而这个答案根本没有解决这个问题。 - Mark Amery__iter__使对象具有可预测的项目顺序来进行迭代。因此,修改上面的示例:class A:
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
def __iter__(self):
yield "a", self._a
yield "b", self._b
yield "c", self._c
def __hash__(self):
return hash(tuple(self))
def __eq__(self, other):
return (isinstance(other, type(self))
and tuple(self) == tuple(other))
(这里对于哈希函数来说,__eq__不是必需的,但实现起来很容易)。
现在添加一些可变成员以查看它如何工作:
a = 2; b = 2.2; c = 'cat'
hash(A(a, b, c)) # -5279839567404192660
dict(A(a, b, c)) # {'a': 2, 'b': 2.2, 'c': 'cat'}
list(A(a, b, c)) # [('a', 2), ('b', 2.2), ('c', 'cat')]
tuple(A(a, b, c)) # (('a', 2), ('b', 2.2), ('c', 'cat'))
只有在尝试将不可哈希的成员放入对象模型时,才会导致事情崩溃:
hash(A(a, b, [1])) # TypeError: unhashable type: 'list'
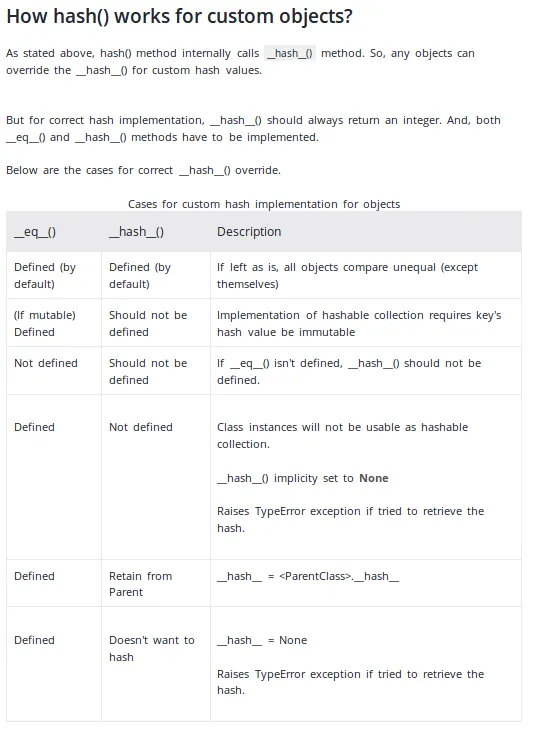
关于何时以及如何实现__hash__函数的非常好的解释在programiz网站上:
以下是提供概述的截图: (检索日期2019-12-13)
class Person:
def __init__(self, age, name):
self.age = age
self.name = name
def __eq__(self, other):
return self.age == other.age and self.name == other.name
def __hash__(self):
print('The hash is:')
return hash((self.age, self.name))
person = Person(23, 'Adam')
print(hash(person))
@dataclass(frozen=True) (Python 3.7)
这个很棒的新功能,除了其他好处之外,还会自动为您定义__hash__和__eq__方法,使其在字典和集合中像通常预期的那样正常工作:
dataclass_cheat.py
from dataclasses import dataclass, FrozenInstanceError
@dataclass(frozen=True)
class MyClass1:
n: int
s: str
@dataclass(frozen=True)
class MyClass2:
n: int
my_class_1: MyClass1
d = {}
d[MyClass1(n=1, s='a')] = 1
d[MyClass1(n=2, s='a')] = 2
d[MyClass1(n=2, s='b')] = 3
d[MyClass2(n=1, my_class_1=MyClass1(n=1, s='a'))] = 4
d[MyClass2(n=2, my_class_1=MyClass1(n=1, s='a'))] = 5
d[MyClass2(n=2, my_class_1=MyClass1(n=2, s='a'))] = 6
assert d[MyClass1(n=1, s='a')] == 1
assert d[MyClass1(n=2, s='a')] == 2
assert d[MyClass1(n=2, s='b')] == 3
assert d[MyClass2(n=1, my_class_1=MyClass1(n=1, s='a'))] == 4
assert d[MyClass2(n=2, my_class_1=MyClass1(n=1, s='a'))] == 5
assert d[MyClass2(n=2, my_class_1=MyClass1(n=2, s='a'))] == 6
# Due to `frozen=True`
o = MyClass1(n=1, s='a')
try:
o.n = 2
except FrozenInstanceError as e:
pass
else:
raise 'error'
正如我们在这个例子中所看到的,哈希值是基于对象内容而不仅仅是实例地址计算的。这就是为什么像这样的东西:
d = {}
d[MyClass1(n=1, s='a')] = 1
assert d[MyClass1(n=1, s='a')] == 1
即使第二个MyClass1(n=1, s='a')是一个完全不同的实例,具有不同的地址,它仍然可以正常工作。
frozen=True是强制性的,否则该类将无法哈希化,否则用户可能会在将对象用作键之后意外修改它们,从而使容器不一致。更多文档:https://docs.python.org/3/library/dataclasses.html
在Python 3.10.7、Ubuntu 22.10上进行了测试。
dataclass进行装饰会增加哪些额外开销? - Naveen Reddy Marthala__init__、__hash__、__eq__相比,有什么不同?基本上没有区别,我相信它会产生相同的类,除了一个单独的函数调用来创建类本身,这通常只运行一次。 - Ciro Santilli OurBigBook.com__init__、__hash__、__eq__相比,有什么不同呢?基本上没有什么不同,我相信它会产生相同的类,只是通过一个单一的函数调用来创建类本身,这通常只运行一次。 - undefined取决于返回的哈希值大小。如果你需要基于四个32位整数的哈希返回一个32位整数,那么会发生碰撞是很简单的逻辑。
我更倾向于比特操作。例如,以下C伪代码:
int a;
int b;
int c;
int d;
int hash = (a & 0xF000F000) | (b & 0x0F000F00) | (c & 0x00F000F0 | (d & 0x000F000F);
如果你只是将浮点数作为其位值而不是实际表示浮点数的值,那么这样的系统也可以适用于浮点数,或许更好。
对于字符串,我没有太多/没有任何想法。
__key函数分解出来所带来的微不足道的开销之外,这几乎是最快的哈希算法。当然,如果属性已知为整数,并且它们的数量不太多,我想你可能可以用一些自定义的哈希算法运行略微得更快,但它可能分布得不太好。hash((self.attr_a, self.attr_b, self.attr_c))会非常快速(并且正确),因为小tuple的创建是特别优化的,并且它把获取和组合哈希的工作推给C内置代码,通常比Python级别的代码更快。 - ShadowRangerNone。我解决它的方法是将对象的ID存储为键,而不仅仅是对象本身。 - Jaswant P__hash__方法,则在更改对象的属性后将返回None。 - Jaswant P