我正在使用Tsai算法进行相机校准。我得到了内参和外参矩阵,但是如何从这些信息中重构出3D坐标?
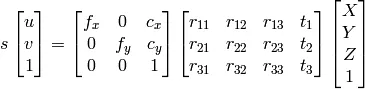
1) 我可以使用高斯消元法来求解X、Y、Z、W,然后将点表示为齐次系统的X/W、Y/W、Z/W。
2) 我可以使用OpenCV文档的方法:
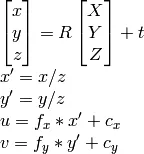
由于我知道u、v、R和t,因此我可以计算X,Y,Z。
然而,这两种方法得出的结果不正确。
我做错了什么?
我正在使用Tsai算法进行相机校准。我得到了内参和外参矩阵,但是如何从这些信息中重构出3D坐标?
1) 我可以使用高斯消元法来求解X、Y、Z、W,然后将点表示为齐次系统的X/W、Y/W、Z/W。
2) 我可以使用OpenCV文档的方法:
由于我知道u、v、R和t,因此我可以计算X,Y,Z。
然而,这两种方法得出的结果不正确。
我做错了什么?
H = K*[r1, r2, t], //eqn 8.1, Hartley and Zisserman
当中K代表相机内部矩阵,r1和r2是旋转矩阵的前两列,R;t是平移向量。
然后通过t3进行归一化处理。
第三列r3发生了什么?我们不使用它吗?不,因为它是姿态的前两列的叉积,所以它是多余的。
现在你有了单应性,可以投影点了。你的二维点是x,y。将它们添加一个z=1,这样它们就变成了三维点。按以下方式对它们进行投影:
p = [x y 1];
projection = H * p; //project
projnorm = projection / p(z); //normalize
如上面的评论所述,将2D图像坐标投影到3D“相机空间”中,本质上需要编造z坐标,因为这些信息在图像中完全丢失。一种解决方案是在投影之前为每个2D图像空间点分配一个虚拟值(z = 1),如Jav_Rock所回答的。
p = [x y 1];
projection = H * p; //project
projnorm = projection / p(z); //normalize
除了这种虚拟解决方案之外,还有一种有趣的替代方案是训练一个模型来预测每个点在重新投影到3D相机空间之前的深度。我尝试过这种方法,并且使用在KITTI数据集中训练的Pytorch CNN对3D边界框进行了高度成功的训练。如果需要代码,我很乐意提供,但贴在这里可能会有点冗长。