在Java中,我通常依赖org.apache.commons.math3.random.EmpiricalDistribution类来执行以下操作:
- 从观察数据中推导出概率分布。
- 从该分布生成随机值。
import numpy as np
import scipy.stats
import matplotlib.pyplot as plt
# This represents the original "empirical" sample -- I fake it by
# sampling from a normal distribution
orig_sample_data = np.random.normal(size=10000)
# Generate a KDE from the empirical sample
sample_pdf = scipy.stats.gaussian_kde(orig_sample_data)
# Sample new datapoints from the KDE
new_sample_data = sample_pdf.resample(10000).T[:,0]
# Histogram of initial empirical sample
cnts, bins, p = plt.hist(orig_sample_data, label='original sample', bins=100,
histtype='step', linewidth=1.5, density=True)
# Histogram of datapoints sampled from KDE
plt.hist(new_sample_data, label='sample from KDE', bins=bins,
histtype='step', linewidth=1.5, density=True)
# Visualize the kde itself
y_kde = sample_pdf(bins)
plt.plot(bins, y_kde, label='KDE')
plt.legend()
plt.show(block=False)
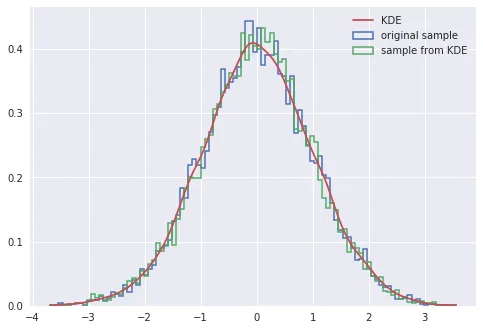
new_sample_data 应该从与原始数据大致相同的分布中绘制出来(在KDE是原始分布的良好近似程度上)。