这是我处理在使用
Caret 包训练模型时,如何在
R 中绘制学习曲线的方法。 我在 R 中使用
Motor Trend Car Road Tests 数据集进行说明。首先,我将
mtcars数据集随机划分为训练集和测试集。用于训练的记录有21条,测试集有13条。在本例中,响应特征是
mpg。请注意保留 HTML 标记。
set.seed(7)
mtcars <- mtcars[sample(nrow(mtcars)),]
mtcarsIndex <- createDataPartition(mtcars$mpg, p = .625, list = F)
mtcarsTrain <- mtcars[mtcarsIndex,]
mtcarsTest <- mtcars[-mtcarsIndex,]
learnCurve <- data.frame(m = integer(21),
trainRMSE = integer(21),
cvRMSE = integer(21))
testY <- mtcarsTest$mpg
trainControl <- trainControl(method="repeatedcv", number=10, repeats=3)
metric <- "RMSE"
for (i in 3:21) {
learnCurve$m[i] <- i
fit.lm <- train(mpg~., data=mtcarsTrain[1:i,], method="lm", metric=metric,
preProc=c("center", "scale"), trControl=trainControl)
learnCurve$trainRMSE[i] <- fit.lm$results$RMSE
prediction <- predict(fit.lm, newdata = mtcarsTest[,-1])
rmse <- postResample(prediction, testY)
learnCurve$cvRMSE[i] <- rmse[1]
}
pdf("LinearRegressionLearningCurve.pdf", width = 7, height = 7, pointsize=12)
plot(log(learnCurve$trainRMSE),type = "o",col = "red", xlab = "Training set size",
ylab = "Error (RMSE)", main = "Linear Model Learning Curve")
lines(log(learnCurve$cvRMSE), type = "o", col = "blue")
legend('topright', c("Train error", "Test error"), lty = c(1,1), lwd = c(2.5, 2.5),
col = c("red", "blue"))
dev.off()
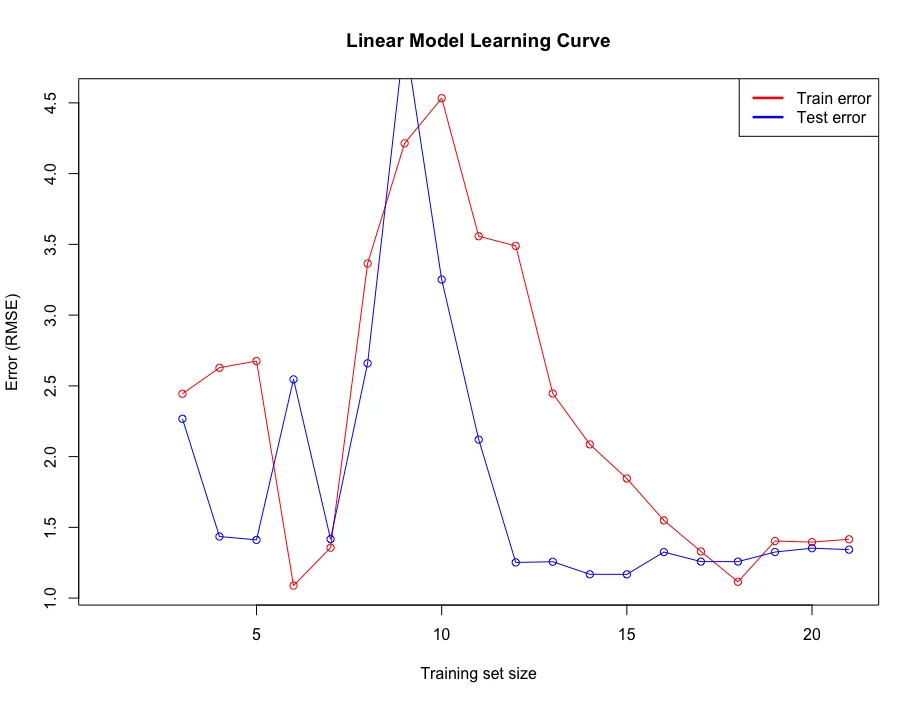
输出的图如下所示: