import pandas as pd
import seaborn as sns
invoices = pd.DataFrame({'FinYear': [2015, 2015, 2014], 'Amount': [10, 10, 15]})
invYr = invoices.groupby(['FinYear']).sum()[['Amount']]
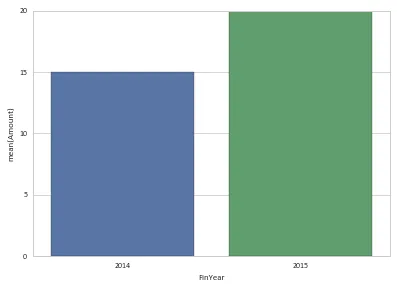
>>> invYr
Amount
FinYear
2014 15
2015 20
您出现错误的原因是,在通过对
invoices进行分组创建
invYr时,
FinYear列变为索引而不再是普通的列。有几种解决方法:
1)一种解决方法是直接指定数据源。您需要为图表指定正确的数据源。如果不指定
data参数,Seaborn就不知道哪个dataframe/series具有'FinYear'或'Amount'这些列名,因为它们只是文本值。您必须指定,例如,
y=invYr.Amount以同时指定要绘制图表的dataframe/series和列名。这里的诀窍在于直接访问dataframe的索引。
sns.barplot(x=invYr.index, y=invYr.Amount)
2) 另外,您可以指定数据源,然后直接引用其列。请注意,分组的数据帧已重置其索引,因此该列再次可用。
sns.barplot(x='FinYear', y='Amount', data=invYr.reset_index())
第三种解决方案是在执行groupby时指定as_index=False,使该列在分组后的数据框中可用。
invYr = invoices.groupby('FinYear', as_index=False).Amount.sum()
sns.barplot(x='FinYear', y='Amount', data=invYr)
以上所有解决方案都会生成下面的相同图形。
data=invYr.reset_index()将索引重置为列。 - BrenBarnDataFrame现在没有索引,看起来很好,就像刚导入的CSV文件一样,但不幸的是,相同的错误信息仍然存在。 - samsinvYr.reset_index()的输出。这不是一个原地操作,所以它可能会打印到REPL并看起来像它“工作了”,但这不是您传递给barplot的内容。 - mwaskom