我有一组大部分符合一条直线,但是也有一些异常值的散点图数据。我一直在使用numpy polyfit来拟合这些数据的线性关系,但是它会受到异常值的影响,导致输出错误的拟合直线:
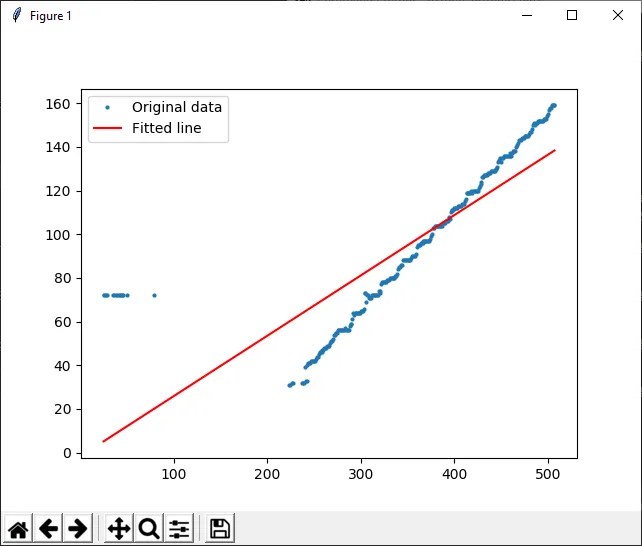
有没有一个函数能给我最佳拟合线的行,而不是适合所有数据点的线?
复制代码:
from numpy.polynomial.polynomial import polyfit
import numpy as np
from matplotlib import pyplot as plt
y = np.array([72, 72, 72, 72, 72, 72, 72, 72, 72, 72, 72, 72, 72, 72, 72, 31, 31, 32, 32, 32, 32, 32, 39, 33, 33, 40, 41, 41, 41, 42, 42, 42, 42, 42, 43, 44, 44, 45, 46, 46, 46, 47, 47, 48, 48, 48, 49, 49, 49, 50, 51, 51, 52, 54, 54, 55, 55, 55, 56, 56, 56, 56, 56, 56, 56, 57, 56, 56, 56, 56, 58, 59, 59, 61, 64, 63, 64, 64, 64, 64, 64, 64, 65, 65, 65, 66, 73, 73, 69, 72, 72, 71, 71, 71, 72, 72, 72, 72, 72, 72, 72, 74, 74, 73, 77, 78, 78, 78, 78, 78, 79, 79, 79, 80, 80, 80, 80, 80, 80, 81, 81, 82, 84, 85, 85, 86, 86, 88, 88, 88, 88, 88, 88, 88, 88, 88, 89, 90, 90, 90, 90, 91, 94, 95, 95, 95, 96, 96, 96, 97, 97, 97, 97, 97, 97, 97, 98, 99, 100, 103, 103, 104, 104, 104, 104, 104, 104, 104, 104, 104, 105, 105, 105, 106, 106, 106, 108, 107, 110, 111, 111, 111, 112, 112, 112, 112, 113, 113, 113, 113, 114, 114, 114, 115, 116, 119, 119, 119, 119, 119, 120, 119, 120, 120, 120, 120, 120, 120, 121, 122, 123, 124, 126, 126, 127, 127, 127, 127, 128, 128, 128, 129, 129, 129, 129, 129, 130, 130, 131, 133, 134, 135, 133, 135, 135, 136, 136, 136, 136, 136, 136, 136, 137, 136, 137, 138, 138, 138, 140, 141, 142, 143, 143, 143, 144, 144, 144, 145, 145, 145, 145, 145, 146, 147, 147, 148, 150, 151, 150, 151, 151, 152, 152, 152, 152, 152, 152, 152, 153, 153, 153, 154, 155, 157, 158, 158, 159, 159, 159, 159])
x = np.array([25, 26, 28, 29, 35, 36, 38, 39, 42, 43, 44, 45, 46, 50, 79, 223, 224, 226, 227, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 374, 375, 376, 377, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 418, 419, 420, 421, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 502, 503, 504, 505, 506, 507])
# Fit with polyfit
b, m = polyfit(x, y, 1)
_ = plt.plot(x, y, 'o', label='Original data', markersize=2)
_ = plt.plot(x, m*x + b, 'r', label='Fitted line')
_ = plt.legend()
plt.show()
如果你好奇的话,我正在尝试使用视差图进行地面平面估计。
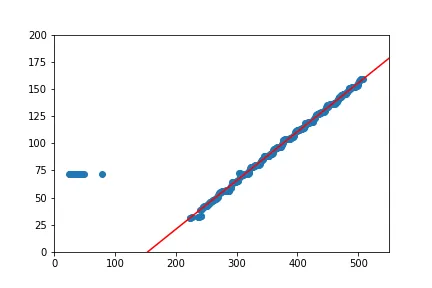
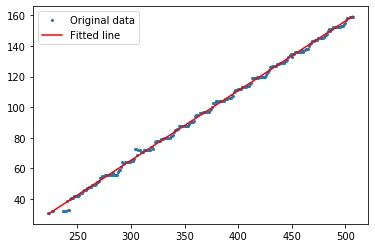
x1=x[x>=200],y1=y[x>=200]。 - DYZ