我有一个包含两列数据(年龄和日期)的dataframe,表示一个人的年龄和当前日期。我想从这些数据中近似计算出生日期。我考虑使用线性模型来拟合数据并找到其截距,但是这种方法并不直接可行。因为Pandas不再支持ols()函数。
import pandas as pd
import seaborn as sns
from pandas import Timestamp
age = [30, 31, 31, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 34, 34]
date = [Timestamp('2001-02-10 00:01:00'),
Timestamp('2001-11-12 00:01:00'),
Timestamp('2002-02-27 00:01:00'),
Timestamp('2002-07-05 00:01:00'),
Timestamp('2002-07-20 00:01:00'),
Timestamp('2002-08-15 00:01:00'),
Timestamp('2002-09-08 00:01:00'),
Timestamp('2002-10-15 00:01:00'),
Timestamp('2002-12-21 00:01:00'),
Timestamp('2003-04-04 00:01:00'),
Timestamp('2003-07-29 00:01:00'),
Timestamp('2003-08-11 00:01:00'),
Timestamp('2004-02-28 00:01:00'),
Timestamp('2005-01-11 00:01:00'),
Timestamp('2005-01-12 00:01:00')]
df = pd.DataFrame({'age': age, 'date': date})
sns.regplot(df.age, df.date)
抛出错误:
类型错误:此数据类型不允许减少操作“均值”
最佳方法是将数据转换为可适配的形式,然后将其转换回日期并估算置信区间。是否有任何可以直接处理pandas.Timestamps的包?例如scikit-learn?
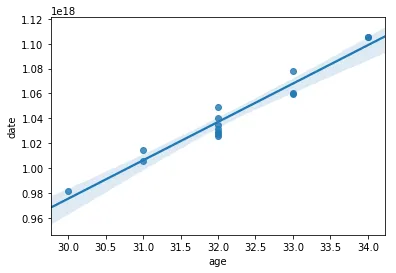
scipy.optimize来拟合你的实际函数。那只是一个快速的示例。 - ALollz