我正在尝试为一个数据集拟合分段线性拟合,如图1所示。
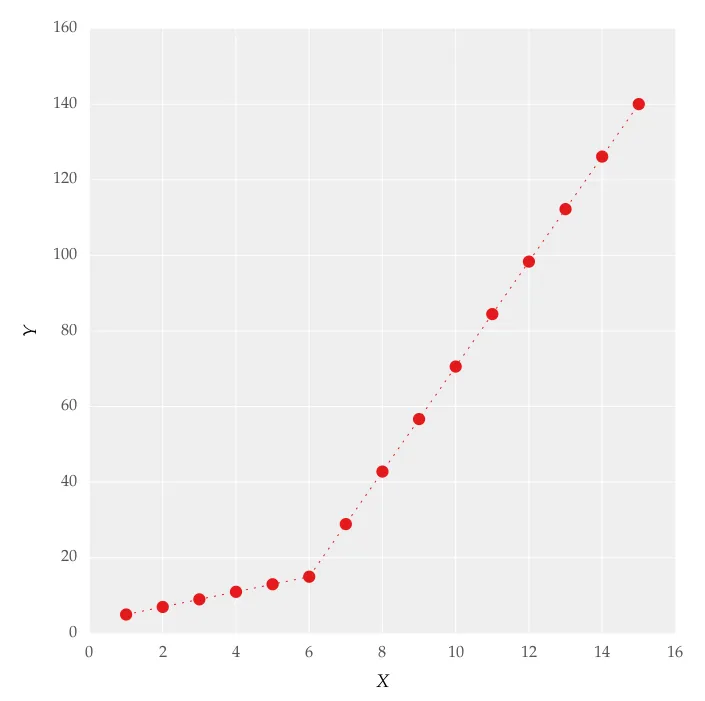
这个图是通过在线上设置得到的。我尝试使用以下代码应用分段线性拟合:
from scipy import optimize
import matplotlib.pyplot as plt
import numpy as np
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ,11, 12, 13, 14, 15])
y = np.array([5, 7, 9, 11, 13, 15, 28.92, 42.81, 56.7, 70.59, 84.47, 98.36, 112.25, 126.14, 140.03])
def linear_fit(x, a, b):
return a * x + b
fit_a, fit_b = optimize.curve_fit(linear_fit, x[0:5], y[0:5])[0]
y_fit = fit_a * x[0:7] + fit_b
fit_a, fit_b = optimize.curve_fit(linear_fit, x[6:14], y[6:14])[0]
y_fit = np.append(y_fit, fit_a * x[6:14] + fit_b)
figure = plt.figure(figsize=(5.15, 5.15))
figure.clf()
plot = plt.subplot(111)
ax1 = plt.gca()
plot.plot(x, y, linestyle = '', linewidth = 0.25, markeredgecolor='none', marker = 'o', label = r'\textit{y_a}')
plot.plot(x, y_fit, linestyle = ':', linewidth = 0.25, markeredgecolor='none', marker = '', label = r'\textit{y_b}')
plot.set_ylabel('Y', labelpad = 6)
plot.set_xlabel('X', labelpad = 6)
figure.savefig('test.pdf', box_inches='tight')
plt.close()
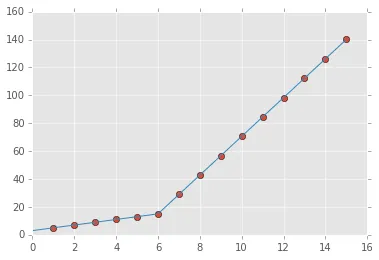
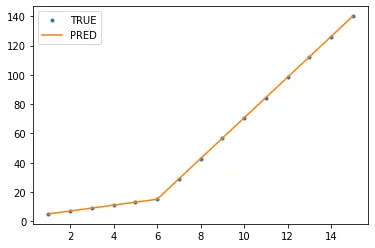
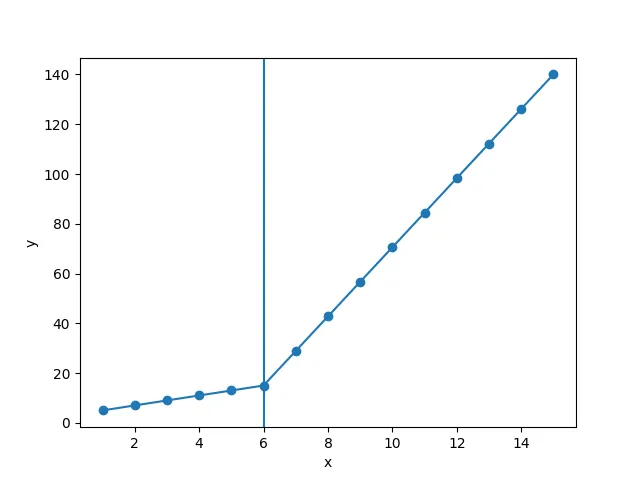
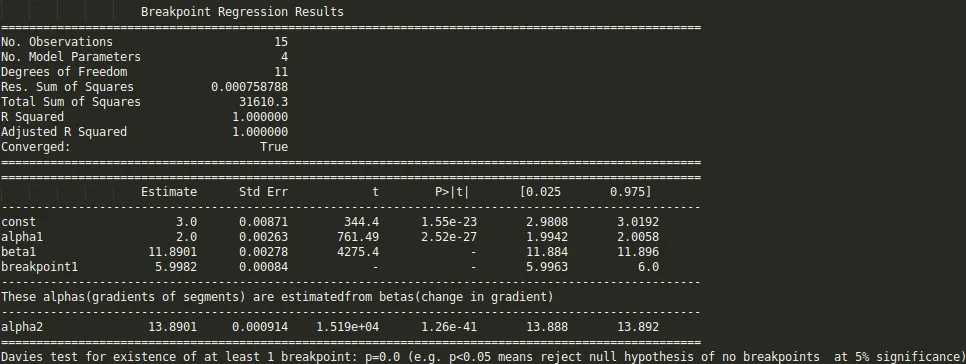
但是这让我得到了图2中的形式拟合,我尝试改变值但是没有任何变化,我无法得到上线的适当匹配。对我来说最重要的要求是如何让Python获取梯度变化点。本质上,我想让Python在适当的范围内识别和拟合两个线性拟合。这在Python中怎么做?
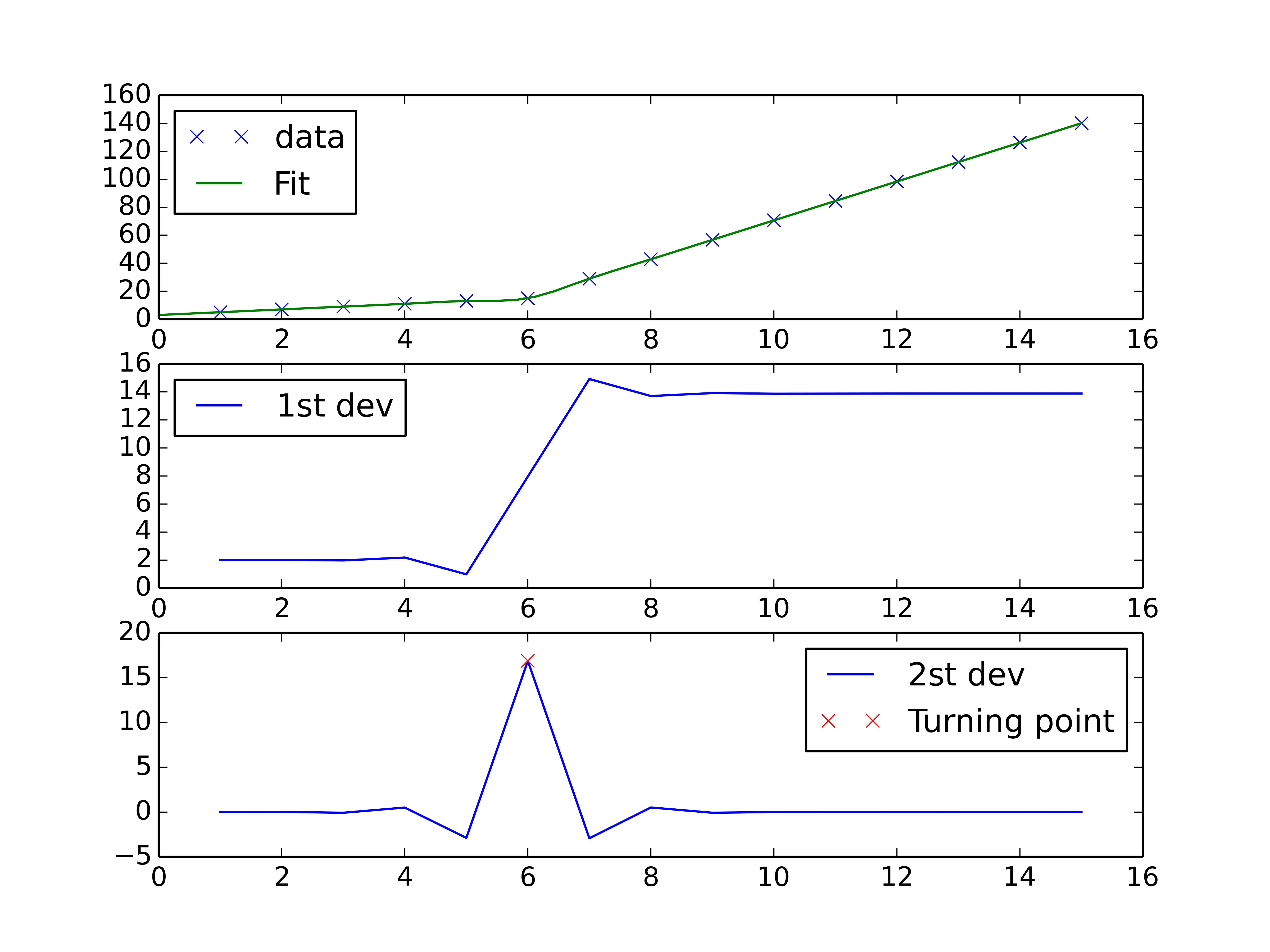
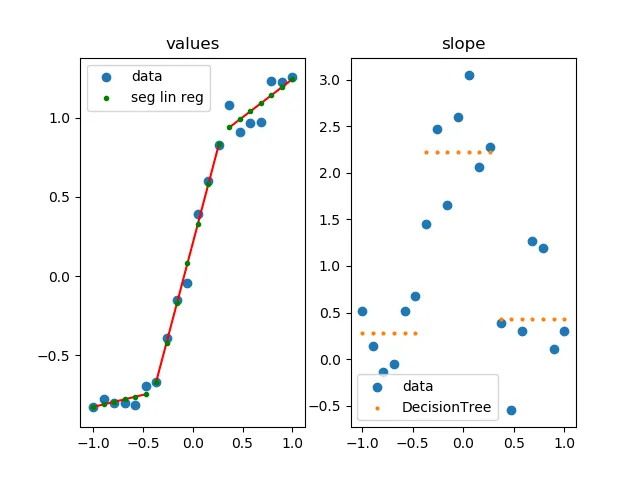
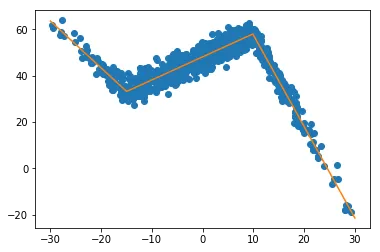
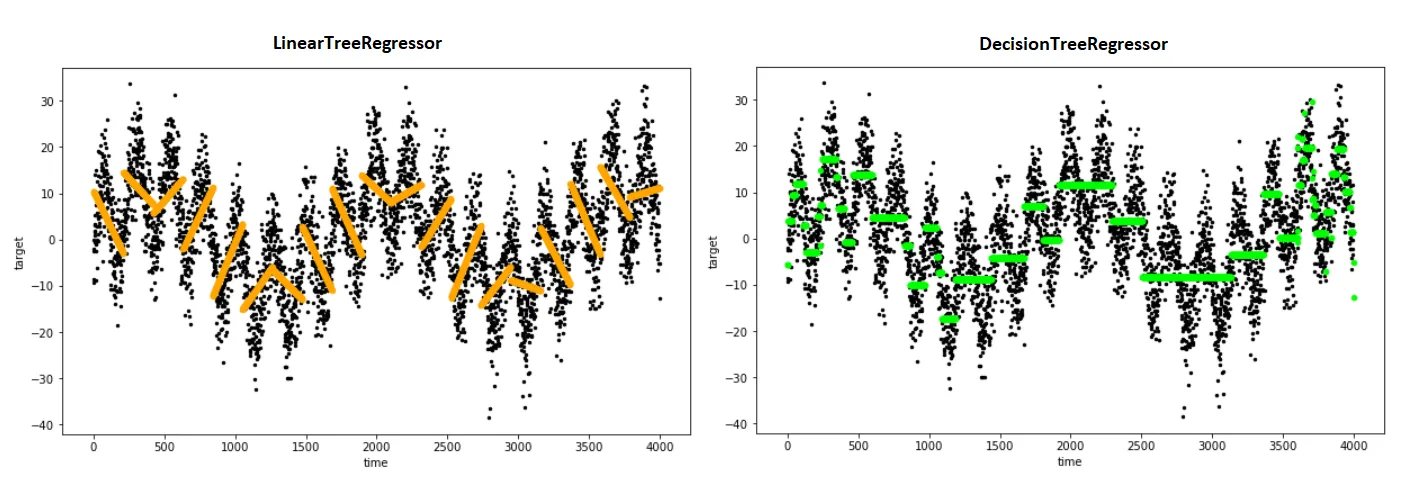
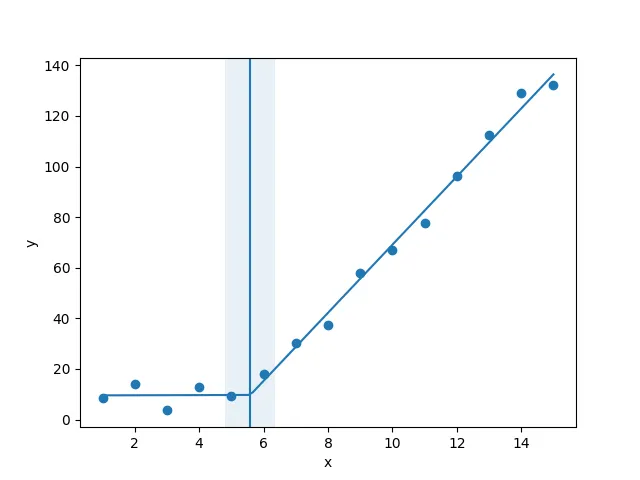
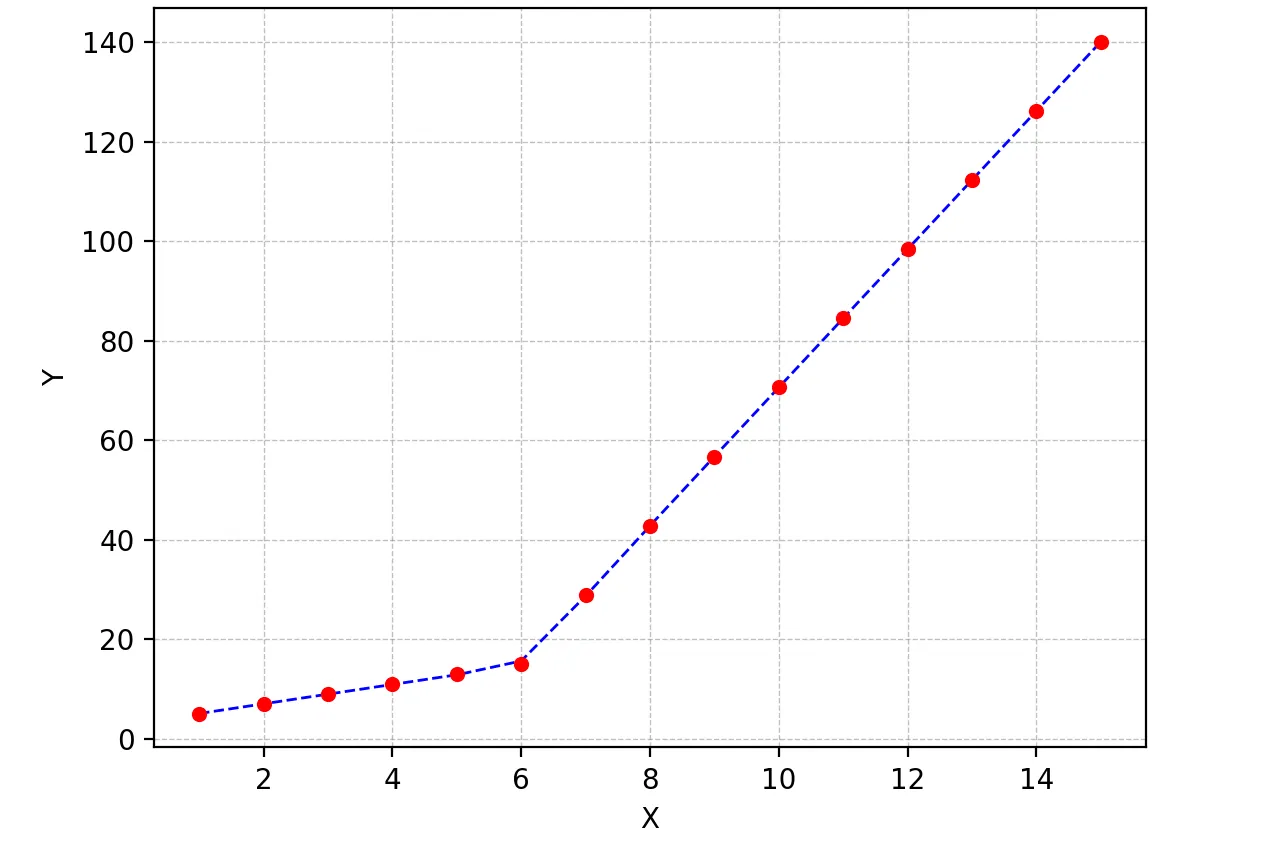
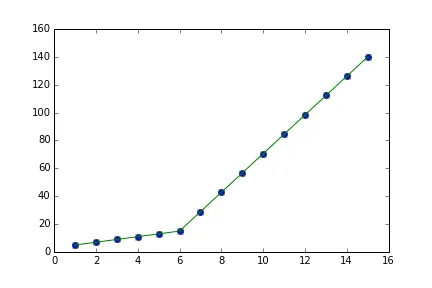
x = np.random.normal(7,5,15)和y= piecewise_linear(x, 5.5,10,0.5,10) +np.random.normal(0,3,x.size)生成了一些带有噪声的点。样本的端点对斜率有很大的影响。 - undefined[1,1,1,1],在其他数据的情况下可能无法收敛到一个良好的拟合结果——它将寻找通过点(1,1)附近的局部最优解。也许考虑选择一个更合理的初始点,如p, e = optimize.curve_fit(piecewise_linear, x, y, p0=[x.mean(), y.mean(),0,0])。 - undefined