我是Pandas的新用户,我喜欢它!
我正试图在Pandas中创建一个数据透视表。一旦我按照自己想要的方式创建了透视表,我想通过列对值进行排名。
我附上了来自Excel的图像,因为以表格形式更容易看清楚我的目标。链接到图片
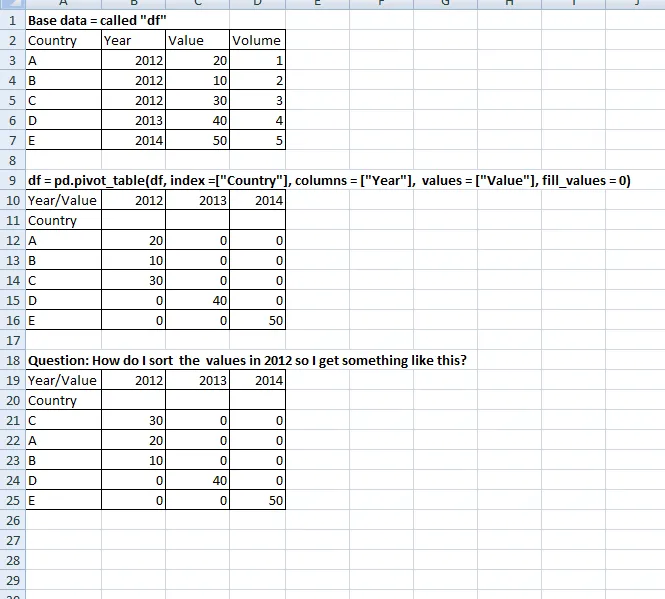{kind=link}
我在stackoverflow上搜索过,但是找不到答案。我尝试使用.sort()方法,但是这并不起作用。任何帮助将不胜感激。
提前致谢
我是Pandas的新用户,我喜欢它!
我正试图在Pandas中创建一个数据透视表。一旦我按照自己想要的方式创建了透视表,我想通过列对值进行排名。
我附上了来自Excel的图像,因为以表格形式更容易看清楚我的目标。链接到图片
我在stackoverflow上搜索过,但是找不到答案。我尝试使用.sort()方法,但是这并不起作用。任何帮助将不胜感激。
提前致谢
这应该能够满足您的要求:
In [1]: df = pd.DataFrame.from_dict([{'Country': 'A', 'Year':2012, 'Value': 20, 'Volume': 1}, {'Country': 'B', 'Year':2012, 'Value': 100, 'Volume': 2}, {'Country': 'C', 'Year':2013, 'Value': 40, 'Volume': 4}])
In [2]: df_pivot = pd.pivot_table(df, index=['Country'], columns = ['Year'],values=['Value'], fill_value=0)
In [3]: df_pivot
Out [4]:
Value
Year 2012 2013
Country
A 20 0
B 100 0
C 0 40
In [5]: df = df_pivot.reindex(df_pivot['Value'].sort_values(by=2012, ascending=False).index)
Out [6]:
Value
Year 2012 2013
Country
B 100 0
A 20 0
C 0 40
基本上,它获取排序值的索引并重新索引初始数据透视表。
df_pivot.reindex,而不是df。 - senna_ananth您可以在数据透视表中按多个列进行排序。在我的情况下,我需要按邮政编码的事故概率和地址的事故概率进行降序排序,并将结果显示在热力图中。
pivot = df.pivot_table(index=['postcode'],values=['probability_at_address','probability_at_postcode'],aggfunc='mean').sort_values(by=['probability_at_address','probability_at_postcode'],ascending=False)
fig,ax=plt.subplots(figsize=(10,20))
sns.heatmap(pivot,cmap="Blues",ax=ax)
plt.show()