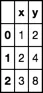
I have a pandas data frame known as "df":
x y
0 1 2
1 2 4
2 3 8
我正在将它分成两个框架,然后尝试合并起来:
df_1 = df[df['x']==1]
df_2 = df[df['x']!=1]
我的目标是按照相同的顺序获取它,但是当我连接时,我得到了以下内容:
frames = [df_1, df_2]
solution = pd.concat(frames)
solution.sort_values(by='x', inplace=False)
x y
1 2 4
2 3 8
0 1 2
问题在于我需要将“x”值按照我提取时的相同顺序放回到新数据框中。有解决方案吗?