我一直在搜索,但没有找到正确的方法来完成以下操作。
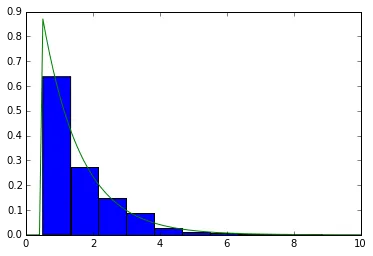
我使用matplotlib制作了一个直方图:
hist, bins, patches = plt.hist(distance, bins=100, normed='True')
从图中可以看出,分布大致是指数分布(泊松分布)。考虑到我的hist和bins数组,我应该如何进行最佳拟合呢?
更新
我采用以下方法:
x = np.float64(bins) # Had some troubles with data types float128 and float64
hist = np.float64(hist)
myexp=lambda x,l,A:A*np.exp(-l*x)
popt,pcov=opt.curve_fit(myexp,(x[1:]+x[:-1])/2,hist)
但是我得到
---> 41 plt.plot(stats.expon.pdf(np.arange(len(hist)),popt),'-')
ValueError: operands could not be broadcast together with shapes (100,) (2,)
spy.optimize.curve_fit,并使用直方图而不是原始数据(根据您的问题)。为此,您首先需要定义一个拟合模型myexp=lambda x,l,A:A*np.exp(-l*x),然后将其用作popt,pcov=spy.optimize.curve_fit(myexp,bins[1:]+bins[:-1])/2,hist)。然后,popt包含(l,A),即指数分布的参数和拟合的前因子。这样更有意义吗? - Andras Deak -- Слава Україніplt.plot(stats.expon.pdf(np.arange(len(hist)),popt),'-'),而是使用plt.plot((x[1:]+x[:-1])/2,myexp((x[1:]+x[:-1])/2,*popt),'-')(或者您喜欢的任何x数组)。 - Andras Deak -- Слава Україні