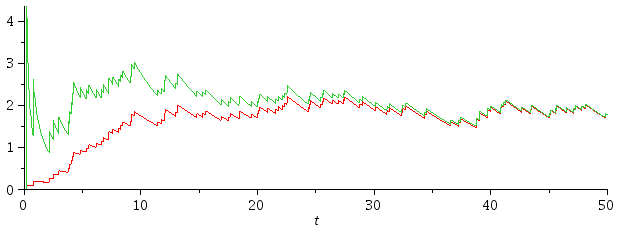
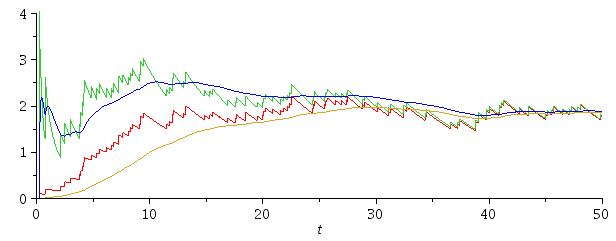
Imagine that I have a set of measurements of x that are taken by many processes x0 ... xN at times t0 ... tN. Let's assume that at time t I want to make an estimate of the current value of x, based on the assumption that there is no long-term trend I know about and that x can be predicted from an algorithm such as exponential smoothing. As we have many processes, and N can get very large, I can't store more than a few values (e.g. the previous state).
One approach here would be to adapt the normal exponential smoothing algorithm. If samples are taken regularly, I would maintain an estimator yn such that: yn = α.yn-1 + ( 1 - α ). xn 这种方法在抽样不规则时并不理想,因为许多样本在一起会产生不成比例的影响。因此,该公式可以改为:
yn = αn.yn-1 + ( 1 - αn ). xn 其中,
αn = e-k.(tn - tn-1) 即根据前两个样本之间的时间间隔动态调整平滑常数。我对这种方法感到满意,并且它似乎有效。这是here给出的第一个答案,并且Eckner在2012年的论文(PDF)中提供了这些技术的良好概述。
现在,我的问题如下。我想将上述内容适应于评估事件发生的速率。偶尔会发生某个事件。使用类似的指数技术,我想要得到该事件发生的速率的估计值。
两种明显的策略是: 1. 使用上一个事件之间的延迟作为数据序列 xn 来使用第一个或第二个技术。 2. 使用上一个事件之间的延迟的倒数(即速率)作为数据序列 xn 来使用第一个或第二个技术。
据我所知,这两种策略都不是好的策略。首先,考虑每500ms发生一次事件(一方面),而另一方面则是200ms和800ms的延迟后才发生一次事件。很明显,它们每秒都会发生两次,因此给出的速率估计应该是相同的。忽略最后一个样本的时间似乎是愚蠢的,因此我将专注于第二个策略。使用延迟(而不是倒数)并不是一个好的预测因素,因为模拟200ms / 800ms的样本流产生了约1.5的估计值(基于倒数的平均值不是平均数的倒数)。
但是,更为重要的是,这两种策略都无法应对实际情况,即突然所有事件停止了很长一段时间。因此,y的“最新”值是上一个事件的值,因此速率的估计从未被计算过。因此,速率看起来是恒定的。当然,如果我是在事后分析数据,这不会成为问题,但我正在实时分析它。
我意识到另一种方法是定期运行一些线程(例如每10秒),并计算此10秒间隔内发生的事件数。这对我的资源非常消耗,因为统计数据通常不需要,而且由于互斥问题,我不愿运行轮询所有内容的线程。因此,我想(某种方式)使用调整状态读取的算法(例如)自上次采样以来的时间。这似乎是一个合理的方法,因为如果性能是在与样本独立选择的时间测量的话,测量时间将平均位于样本之间时间段的中点,因此未经平滑处理的速率估计值将是自上次采样以来的时间的倒数的一半。为了使事情更加复杂,我的测量时间将不独立于样本。
我感觉这个问题的答案很简单,但是它却让我无法理解。我觉得正确的方法是假设事件服从泊松分布,并根据上一个样本以及某种形式的移动平均值来推导出λ的估计值,但我的统计学知识太生疏了,无法使其有效运作。
这个问题有一个相似的问题here,但答案似乎并不令人满意(希望我解释清楚了)。我还想补充一下,卡尔曼滤波器似乎过于繁重,因为我只需要估计一个变量,并且对它一无所知。还有其他一些类似的问题,其中大部分建议保留大量的值(从内存角度来看这不现实),或者没有解决以上两个问题。
One approach here would be to adapt the normal exponential smoothing algorithm. If samples are taken regularly, I would maintain an estimator yn such that: yn = α.yn-1 + ( 1 - α ). xn 这种方法在抽样不规则时并不理想,因为许多样本在一起会产生不成比例的影响。因此,该公式可以改为:
yn = αn.yn-1 + ( 1 - αn ). xn 其中,
αn = e-k.(tn - tn-1) 即根据前两个样本之间的时间间隔动态调整平滑常数。我对这种方法感到满意,并且它似乎有效。这是here给出的第一个答案,并且Eckner在2012年的论文(PDF)中提供了这些技术的良好概述。
现在,我的问题如下。我想将上述内容适应于评估事件发生的速率。偶尔会发生某个事件。使用类似的指数技术,我想要得到该事件发生的速率的估计值。
两种明显的策略是: 1. 使用上一个事件之间的延迟作为数据序列 xn 来使用第一个或第二个技术。 2. 使用上一个事件之间的延迟的倒数(即速率)作为数据序列 xn 来使用第一个或第二个技术。
据我所知,这两种策略都不是好的策略。首先,考虑每500ms发生一次事件(一方面),而另一方面则是200ms和800ms的延迟后才发生一次事件。很明显,它们每秒都会发生两次,因此给出的速率估计应该是相同的。忽略最后一个样本的时间似乎是愚蠢的,因此我将专注于第二个策略。使用延迟(而不是倒数)并不是一个好的预测因素,因为模拟200ms / 800ms的样本流产生了约1.5的估计值(基于倒数的平均值不是平均数的倒数)。
但是,更为重要的是,这两种策略都无法应对实际情况,即突然所有事件停止了很长一段时间。因此,y的“最新”值是上一个事件的值,因此速率的估计从未被计算过。因此,速率看起来是恒定的。当然,如果我是在事后分析数据,这不会成为问题,但我正在实时分析它。
我意识到另一种方法是定期运行一些线程(例如每10秒),并计算此10秒间隔内发生的事件数。这对我的资源非常消耗,因为统计数据通常不需要,而且由于互斥问题,我不愿运行轮询所有内容的线程。因此,我想(某种方式)使用调整状态读取的算法(例如)自上次采样以来的时间。这似乎是一个合理的方法,因为如果性能是在与样本独立选择的时间测量的话,测量时间将平均位于样本之间时间段的中点,因此未经平滑处理的速率估计值将是自上次采样以来的时间的倒数的一半。为了使事情更加复杂,我的测量时间将不独立于样本。
我感觉这个问题的答案很简单,但是它却让我无法理解。我觉得正确的方法是假设事件服从泊松分布,并根据上一个样本以及某种形式的移动平均值来推导出λ的估计值,但我的统计学知识太生疏了,无法使其有效运作。
这个问题有一个相似的问题here,但答案似乎并不令人满意(希望我解释清楚了)。我还想补充一下,卡尔曼滤波器似乎过于繁重,因为我只需要估计一个变量,并且对它一无所知。还有其他一些类似的问题,其中大部分建议保留大量的值(从内存角度来看这不现实),或者没有解决以上两个问题。