我已经挣扎了一段时间,但基本上我已经设置了一个脚本,目前可以读取包含多列数据的文本文件,其中第一列读取时间,如下所示:
Time_(s) Mass_Flow_(kg/s) T_in_pipe(C) T_in_water(C) T_out_pipe(C) T_out_water(C)
0 1.2450 16.9029 16.8256 16.6234 16.6204
2.8700 1.2450 16.8873 16.8094 16.6237 19.6507
5.6600 1.2450 16.8889 16.8229 19.1406 29.1320
8.7800 1.2450 16.8875 16.8236 24.1325 34.9077
11.6200 1.2450 16.8794 16.8040 28.3927 38.5443
16.0600 1.2450 16.8615 16.7942 33.7205 42.4149
18.8900 1.2450 16.8512 16.7938 36.2797 44.1221
23.0200 1.2450 16.8319 16.7903 39.2102 46.1857
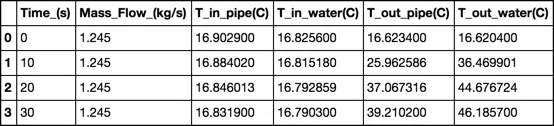
使用pandas工具pd.read_csv,我有一个包含每个列标题的数据帧。现在,我想重新采样这些数据,以便输出数据帧包含所有数据列,并且间隔由用户指定为固定时间间隔。例如,如果选择时间步长为10秒,则使用线性插值的输出将如下所示:
Time_(s) T_out_pipe(C) T_out_water(C) T_in_pipe(C) T_in_water(C) Mass_Flow(kg/s)
0 16.9028797149658 16.8256435394287 16.6234245300293 16.6203994750977 1.24500000476837
10 16.8840274810791 16.8151550292969 25.9625988006592 36.4699172973633 1.24500000476837
20 16.8460464477539 16.7928314208984 37.0673408508301 44.6767387390137 1.24500000476837
30 16.8223628997803 16.7767677307129 42.5221672058106 48.3903617858887 1.24500000476837
我曾经看到过使用pandas中的resample函数进行类似操作的事情,但我所看到的所有示例都要求时间数据格式为年/月/日/小时/分钟/秒。我可以将第一列转换为这样的时间序列,但在我的情况下,我认为有更简单的方法来完成此操作。如果其他人已经处理过类似的转换过程,我将非常感激他们的见解。
谢谢,
Keith