我正在使用Python 2.7,有时间戳和相应的值。我想将这些值设置为每秒钟一个值的时间基准,即最后一次测量的值。所以:
[[1, 4, 6],
[15, 17, 12]]
to:
[[1, 2, 3, 4, 4, 6],
[15, 15, 15, 17, 17, 12]]
我想到了这个方法,它可以实现我想要的功能,但一定有更加优雅的方式。有人知道吗?
import numpy as np
#Example data:
origdata= {}
origdata['time'] = [4, 26, 37, 51, 59, 71, 93]
origdata['vals'] = [17, 5, 43, 21, 14, 8, np.NaN]
extratime = [t-1 for t in origdata['time']]
data={}
data['time'] = np.concatenate((origdata['time'][:-1], extratime[1:]), axis=0)
data['vals'] = np.concatenate((origdata['vals'][:-1], origdata['vals'][:-1]), axis=0)
sorter = data['time'].argsort()
data['time'] = data['time'][sorter]
data['vals'] = data['vals'][sorter]
filledOutData = {}
filledOutData['time'] = range(data['time'][0], data['time'][-1])
filledOutData['vals'] = np.interp(filledOutData['time'], data['time'], data['vals'])
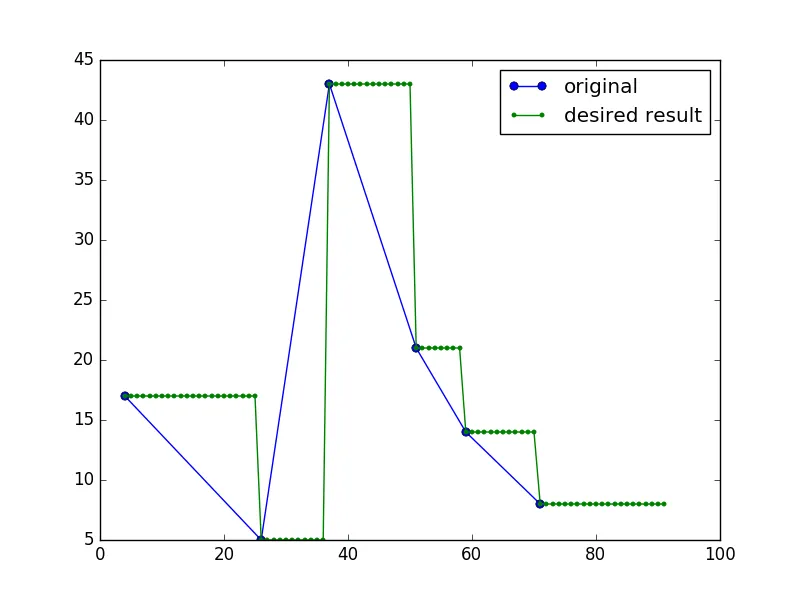
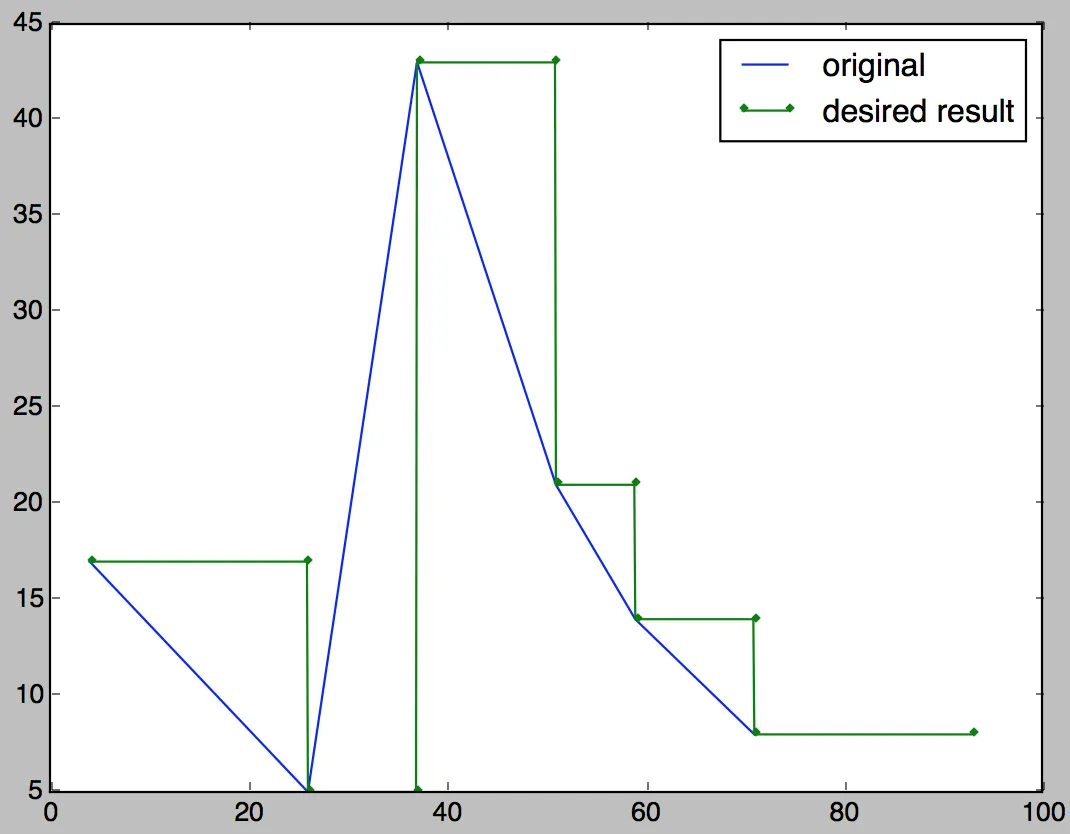
使用以下代码将原始数据和期望结果绘制出来可得到下面的图像:
import matplotlib.pyplot as plt
plt.plot(origdata['time'], origdata['vals'], '-o', filledOutData['time'], filledOutData['vals'], '.-')
plt.legend(['original', 'desired result'])
plt.show
scipy.interpolate.interp1d与kind='zero'看起来很有前途。 - Swier