关键要点:
1. 使用向量化。
2. 对代码进行速度分析!不要假设某个方法更快,因为你认为它更快;进行速度分析并证明它确实更快。结果可能会让你惊讶。
如何在Pandas的DataFrame中进行迭代而不进行迭代
经过几周的努力,我总结了以下方法:
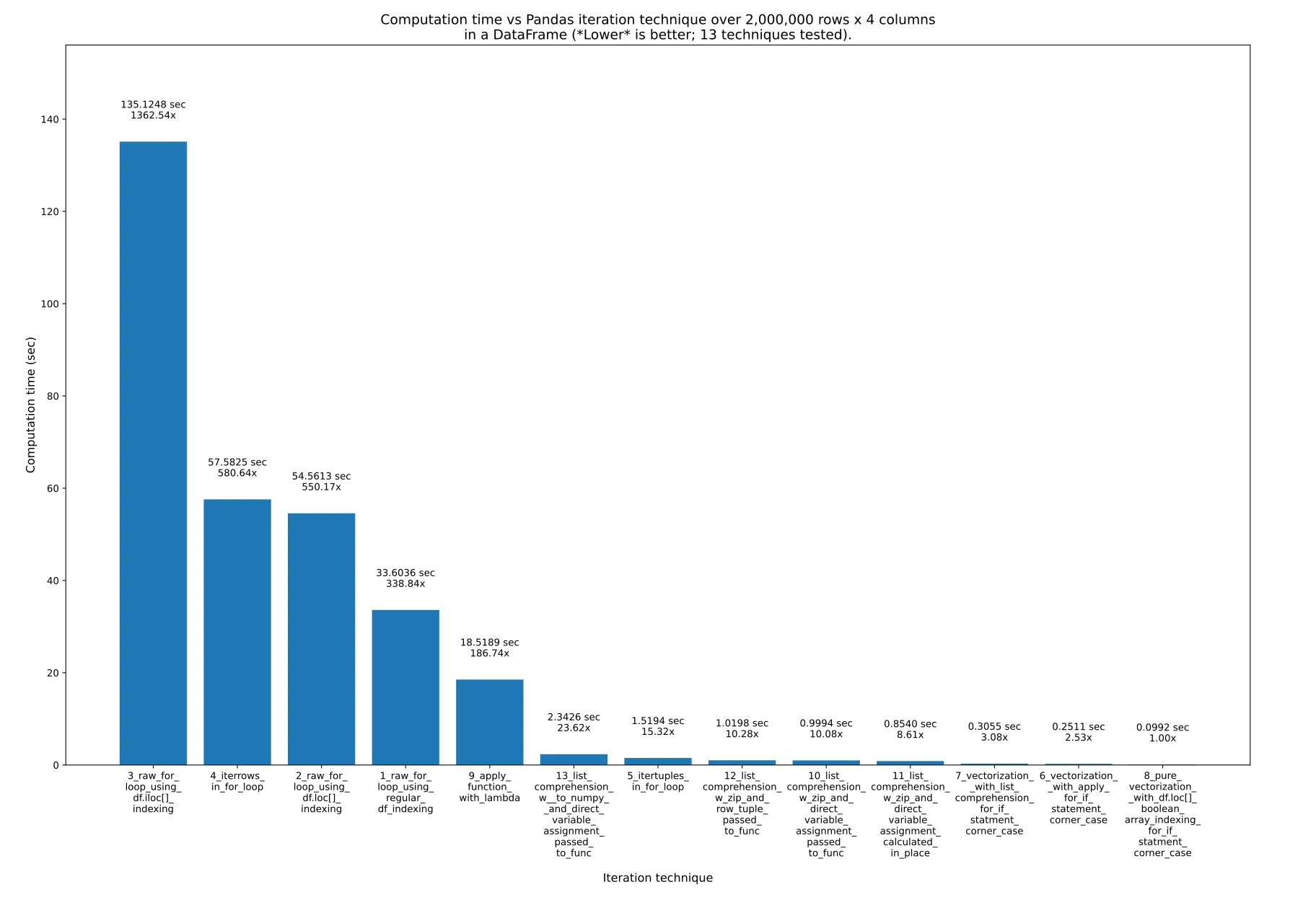
这里有13种迭代Pandas DataFrame的技巧。正如你所看到的,所需时间差异巨大。最快的技巧比最慢的技巧快了约1363倍!关键是,就像@cs95在这里所说的那样,
不要进行迭代!而是使用向量化("数组编程")代替。这实际上意味着你应该直接在数学公式中使用数组,而不是手动迭代数组。当然,底层对象必须支持这一点,但Numpy和Pandas都是支持的。
在Pandas中有很多使用向量化的方法,你可以在下面的图表和我的示例代码中看到。当直接使用数组时,底层循环仍然会发生,但是使用的是(我认为)经过优化的底层C代码,而不是原始的Python代码。
结果
测试了13种技术,编号从1到13。每个柱状图下方标有技术编号和名称。每个柱状图上方显示了总计算时间。其下方是乘数,用于显示比最右边的最快技术所花费的时间长多少:
来自我的eRCaGuy_hello_world存储库中的pandas_dataframe_iteration_vs_vectorization_vs_list_comprehension_speed_tests.svg(由此代码生成)。
摘要
列表推导和向量化(可能还包括布尔索引)是你所需要的全部。
使用列表推导(好)和向量化(最佳)。我认为纯向量化总是可能的,但在复杂计算中可能需要额外的工作。在这个答案中搜索"布尔索引"、"布尔数组"和"布尔掩码"(这三者是同一回事),以查看一些更复杂的情况,纯向量化可以在其中使用。
以下是13种技术,按照最快到最慢的顺序列出。我建议永远不要使用最后(最慢)的3到4种技术。
8_pure_vectorization__with_df.loc[]_boolean_array_indexing_for_if_statment_corner_case6_vectorization__with_apply_for_if_statement_corner_case7_vectorization__with_list_comprehension_for_if_statment_corner_case11_list_comprehension_w_zip_and_direct_variable_assignment_calculated_in_place10_list_comprehension_w_zip_and_direct_variable_assignment_passed_to_func12_list_comprehension_w_zip_and_row_tuple_passed_to_func5_itertuples_in_for_loop13_list_comprehension_w__to_numpy__and_direct_variable_assignment_passed_to_func9_apply_function_with_lambda1_raw_for_loop_using_regular_df_indexing2_raw_for_loop_using_df.loc[]_indexing4_iterrows_in_for_loop3_raw_for_loop_using_df.iloc[]_indexing
经验法则:
技巧3、4和2绝对不能使用。它们非常慢,没有任何优势。但要记住:这不是索引技术(如.loc[]或.iloc[])使这些技巧变糟糕,而是它们所在的for循环使它们变糟糕!例如,我在最快的(纯向量化)方法中使用.loc[]!所以,以下是三种最慢的技巧,绝对不能使用:
1. 3_raw_for_loop_using_df.iloc[]_indexing
2. 4_iterrows_in_for_loop
3. 2_raw_for_loop_using_df.loc[]_indexing
技巧1_raw_for_loop_using_regular_df_indexing也不应使用,但如果你要使用原始for循环,它比其他方法更快。
.apply()函数(9_apply_function_with_lambda)可以使用,但一般情况下我会避免使用它。然而,技巧6_vectorization__with_apply_for_if_statement_corner_case比技巧7_vectorization__with_list_comprehension_for_if_statment_corner_case表现更好,这很有趣。
列表推导式很棒!它不是最快的,但使用起来很简单且非常快!
它的好处是可以与任何用于处理单个值或数组值的函数一起使用。这意味着你可以在函数内部使用非常复杂的if语句和其他操作。因此,它在使用外部计算函数时提供了很大的灵活性,代码可读性强,可重复使用,同时仍然具有很高的速度!
向量化是最快且最好的方法,适用于简单的方程。你可以选择仅在方程的更复杂部分使用类似.apply()或列表推导式的方法,同时仍然轻松地使用向量化处理其余部分。
纯向量化是绝对最快且最好的方法,如果你愿意付出努力使其工作的话。
1. 对于简单情况,应使用纯向量化。
2. 对于复杂情况、if语句等,纯向量化也可以通过布尔索引来实现,但可能增加额外的工作量并降低可读性。因此,你可以选择仅对这些边缘情况使用列表推导式(通常是最佳选择)或.apply()(通常较慢,但不总是)来处理计算的其余部分。例如,参见技巧7_vectorization__with_list_comprehension_for_if_statment_corner_case和技巧6_vectorization__with_apply_for_if_statement_corner_case。
测试数据
假设我们有以下的Pandas DataFrame。它有200万行和4列(A,B,C和D),每列的值都是从-1000到1000的随机值:
df =
A B C D
0 -365 842 284 -942
1 532 416 -102 888
2 397 321 -296 -616
3 -215 879 557 895
4 857 701 -157 480
... ... ... ... ...
1999995 -101 -233 -377 -939
1999996 -989 380 917 145
1999997 -879 333 -372 -970
1999998 738 982 -743 312
1999999 -306 -103 459 745
我是这样生成这个DataFrame的:
import numpy as np
import pandas as pd
MIN_VAL = -1000
MAX_VAL = 1000
NUM_ROWS = 2_000_000
NUM_COLS = 4
data = np.random.randint(MIN_VAL, MAX_VAL, size=(NUM_ROWS, NUM_COLS))
df_original = pd.DataFrame(data, columns=["A", "B", "C", "D"])
print(f"df = \n{df_original}")
测试方程/计算
我想要展示这些技术在非平凡的函数或方程上是可行的,所以我故意设计了这个需要计算的方程,它需要:
if语句- DataFrame中多列的数据
- DataFrame中多行的数据
我们将为每一行计算的方程如下。我随意编写了它,但我认为它足够复杂,你可以在我所做的基础上扩展,以在Pandas中执行任何你想要的方程,并实现完全向量化:
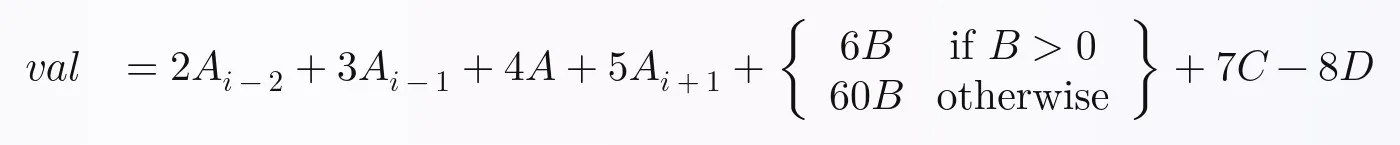
在Python中,上述方程可以这样写:
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
+ ((6 * B) if B > 0 else (60 * B))
+ 7 * C
- 8 * D
)
或者,你可以这样写:
if B > 0:
B_new = 6 * B
else:
B_new = 60 * B
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
+ B_new
+ 7 * C
- 8 * D
)
这两个都可以封装成一个函数。例如:
def calculate_val(
A_i_minus_2,
A_i_minus_1,
A,
A_i_plus_1,
B,
C,
D):
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
+ ((6 * B) if B > 0 else (60 * B))
+ 7 * C
- 8 * D
)
return val
技术方法
完整的代码可以在我的python/pandas_dataframe_iteration_vs_vectorization_vs_list_comprehension_speed_tests.py文件中下载和运行,该文件位于我的eRCaGuy_hello_world存储库中。
以下是所有13种技术的代码:
1_raw_for_loop_using_regular_df_indexing
val = [np.NAN]*len(df)
for i in range(len(df)):
if i < 2 or i > len(df)-2:
continue
val[i] = calculate_val(
df["A"][i-2],
df["A"][i-1],
df["A"][i],
df["A"][i+1],
df["B"][i],
df["C"][i],
df["D"][i],
)
df["val"] = val
2_raw_for_loop_using_df.loc[]_indexing
val = [np.NAN]*len(df)
for i in range(len(df)):
if i < 2 or i > len(df)-2:
continue
val[i] = calculate_val(
df.loc[i-2, "A"],
df.loc[i-1, "A"],
df.loc[i, "A"],
df.loc[i+1, "A"],
df.loc[i, "B"],
df.loc[i, "C"],
df.loc[i, "D"],
)
df["val"] = val
3_raw_for_loop_using_df.iloc[]_indexing
i_A = 0
i_B = 1
i_C = 2
i_D = 3
val = [np.NAN]*len(df)
for i in range(len(df)):
if i < 2 or i > len(df)-2:
continue
val[i] = calculate_val(
df.iloc[i-2, i_A],
df.iloc[i-1, i_A],
df.iloc[i, i_A],
df.iloc[i+1, i_A],
df.iloc[i, i_B],
df.iloc[i, i_C],
df.iloc[i, i_D],
)
df["val"] = val
4_iterrows_in_for_loop
val = [np.NAN]*len(df)
for index, row in df.iterrows():
if index < 2 or index > len(df)-2:
continue
val[index] = calculate_val(
df["A"][index-2],
df["A"][index-1],
row["A"],
df["A"][index+1],
row["B"],
row["C"],
row["D"],
)
df["val"] = val
对于所有下面的示例,我们首先需要通过添加具有前一个和后一个值的列来准备数据框:A_(i-2), A_(i-1)和A_(i+1)。这些列在数据框中将分别命名为A_i_minus_2,A_i_minus_1和A_i_plus_1。
df_original["A_i_minus_2"] = df_original["A"].shift(2)
df_original["A_i_minus_1"] = df_original["A"].shift(1)
df_original["A_i_plus_1"] = df_original["A"].shift(-1)
df_original.iloc[:2, :] = np.NAN
df_original.iloc[-1:, :] = np.NAN
运行上面的向量化代码以生成这3个新列总共花费了
0.044961秒。
现在继续介绍其他的技术:
5_itertuples_in_for_loop
val = [np.NAN]*len(df)
for row in df.itertuples():
val[row.Index] = calculate_val(
row.A_i_minus_2,
row.A_i_minus_1,
row.A,
row.A_i_plus_1,
row.B,
row.C,
row.D,
)
df["val"] = val
6_vectorization__with_apply_for_if_statement_corner_case
def calculate_new_column_b_value(b_value):
b_value_new = (6 * b_value) if b_value > 0 else (60 * b_value)
return b_value_new
df["B_new"] = df["B"].apply(calculate_new_column_b_value)
df["val"] = (
2 * df["A_i_minus_2"]
+ 3 * df["A_i_minus_1"]
+ 4 * df["A"]
+ 5 * df["A_i_plus_1"]
+ df["B_new"]
+ 7 * df["C"]
- 8 * df["D"]
)
7_vectorization__with_list_comprehension_for_if_statment_corner_case
df["B_new"] = [
calculate_new_column_b_value(b_value) for b_value in df["B"]
]
df["val"] = (
2 * df["A_i_minus_2"]
+ 3 * df["A_i_minus_1"]
+ 4 * df["A"]
+ 5 * df["A_i_plus_1"]
+ df["B_new"]
+ 7 * df["C"]
- 8 * df["D"]
)
8_pure_vectorization__with_df.loc[]_boolean_array_indexing_for_if_statment_corner_case
This uses boolean indexing, AKA: a boolean mask, to accomplish the equivalent of the if statement in the equation. In this way, pure vectorization can be used for the entire equation, thereby maximizing performance and speed.
df["B_new"] = df.loc[df["B"] > 0, "B"] * 6
df.loc[df["B"] <= 0, "B_new"] = df.loc[df["B"] <= 0, "B"] * 60
df["val"] = (
2 * df["A_i_minus_2"]
+ 3 * df["A_i_minus_1"]
+ 4 * df["A"]
+ 5 * df["A_i_plus_1"]
+ df["B_new"]
+ 7 * df["C"]
- 8 * df["D"]
)
9_apply_function_with_lambda
df["val"] = df.apply(
lambda row: calculate_val(
row["A_i_minus_2"],
row["A_i_minus_1"],
row["A"],
row["A_i_plus_1"],
row["B"],
row["C"],
row["D"]
),
axis='columns'
)
10_list_comprehension_w_zip_and_direct_variable_assignment_passed_to_func
df["val"] = [
calculate_val(
A_i_minus_2,
A_i_minus_1,
A,
A_i_plus_1,
B,
C,
D
) for A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D
in zip(
df["A_i_minus_2"],
df["A_i_minus_1"],
df["A"],
df["A_i_plus_1"],
df["B"],
df["C"],
df["D"]
)
]
11_list_comprehension_w_zip_and_direct_variable_assignment_calculated_in_place
df["val"] = [
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
+ ((6 * B) if B > 0 else (60 * B))
+ 7 * C
- 8 * D
for A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D
in zip(
df["A_i_minus_2"],
df["A_i_minus_1"],
df["A"],
df["A_i_plus_1"],
df["B"],
df["C"],
df["D"]
)
]
12_list_comprehension_w_zip_and_row_tuple_passed_to_func
df["val"] = [
calculate_val(
row[0],
row[1],
row[2],
row[3],
row[4],
row[5],
row[6],
) for row
in zip(
df["A_i_minus_2"],
df["A_i_minus_1"],
df["A"],
df["A_i_plus_1"],
df["B"],
df["C"],
df["D"]
)
]
13_list_comprehension_w__to_numpy__and_direct_variable_assignment_passed_to_func
df["val"] = [
calculate_val(
A_i_minus_2,
A_i_minus_1,
A,
A_i_plus_1,
B,
C,
D
) for A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D
in df[[
"A_i_minus_2",
"A_i_minus_1",
"A",
"A_i_plus_1",
"B",
"C",
"D"
]].to_numpy()
]
这里再次呈现结果:
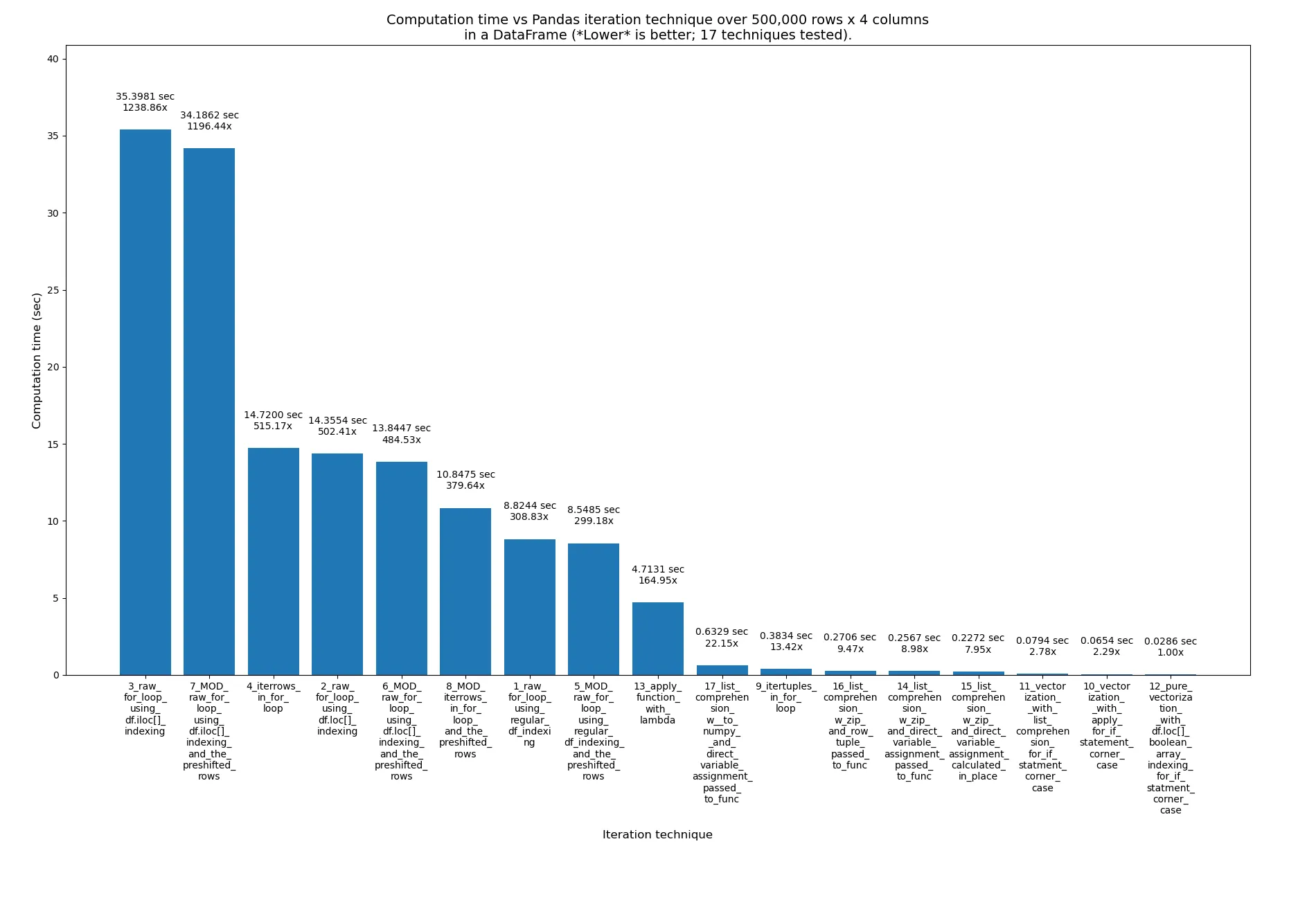
使用预移位行在4个for循环技术中也是一种方法
我想看看去掉这个if检查,使用预移位行在4个for循环技术中是否会有很大的影响:
if i < 2 or i > len(df)-2:
continue
...所以我用这些修改创建了这个文件:pandas_dataframe_iteration_vs_vectorization_vs_list_comprehension_speed_tests_mod.py。在文件中搜索“MOD:”以找到4种新的修改技术。
只有轻微的改进。现在这17种技术的结果如下,其中4种新技术的名称开头附近有单词_MOD_,紧跟在它们的编号之后。这次是超过500k行,而不是2M:
更多关于.iterrtuples()
使用.iterrtuples()时实际上有更多细微之处。要深入了解其中一些细节,请阅读Romain Capron的这个回答。这是我根据他的结果制作的柱状图:
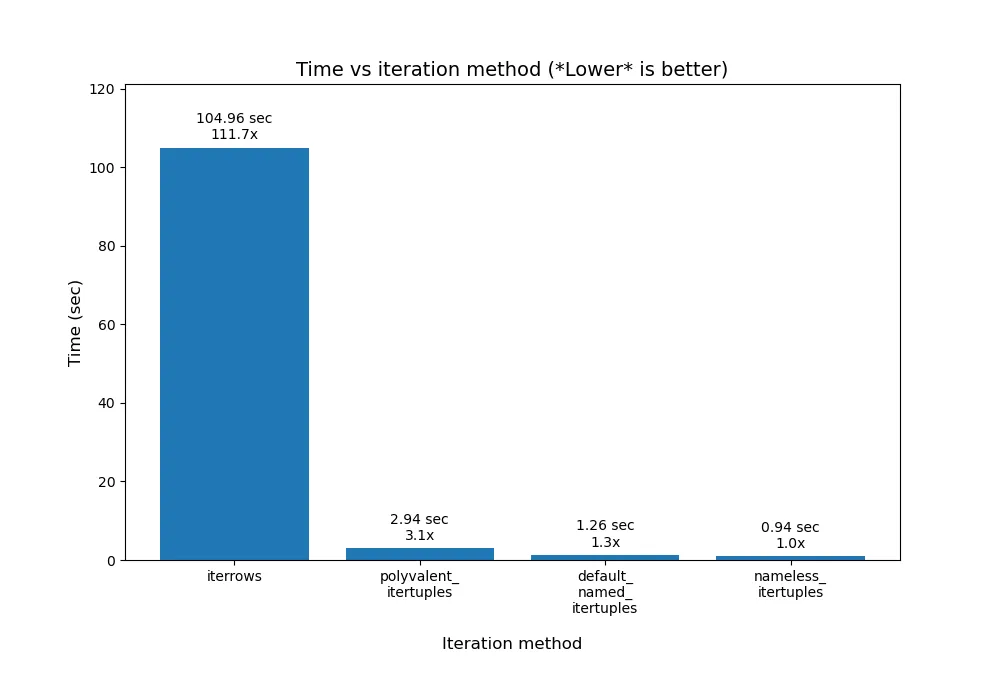
我的绘图代码用于他的结果,位于我的
python/pandas_plot_bar_chart_better_GREAT_AUTOLABEL_DATA.py文件中,该文件存放在我的
eRCaGuy_hello_world存储库中。
未来的工作
使用Cython(将Python编译为C代码)或者只是通过Python调用原始的C函数可能会更快,但对于这些测试我不会这样做。我只会针对大规模优化进行研究和速度测试。
我目前不了解Cython,也没有学习的需求。正如您在上面所看到的,仅仅使用纯向量化的正确方法已经运行得非常快,仅需0.1秒即可处理200万行数据,即每秒处理2000万行。
参考资料
以下是一些官方Pandas文档,特别是这里的DataFrame文档:
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html。
这个很棒的回答是由@cs95提供的,我特别学到了如何使用列表推导式来迭代DataFrame:
This excellent answer by @cs95。
这个关于`itertuples()`的回答是由@Romain Capron提供的,我仔细研究并进行了编辑和格式化:
This answer about `itertuples()`, by @Romain Capron。
所有这些代码都是我自己写的,但我想指出,我与GitHub Copilot(主要是)、Bing AI和ChatGPT进行了数十次的交流,以便找出许多这些技巧并在编写代码时进行调试。
Bing Chat为我生成了漂亮的LaTeX方程式,使用了以下提示。当然,我也验证了输出结果:
将这段Python代码转换为我可以粘贴到Stack Overflow上的漂亮方程式:
```python
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
# Python三元运算符;不要忘记在整个三元表达式周围加上括号!
+ ((6 * B) if B > 0 else (60 * B))
+ 7 * C
- 8 * D
)
```
另请参阅
这个答案也发布在我的个人网站上:
https://gabrielstaples.com/python_iterate_over_pandas_dataframe/
https://en.wikipedia.org/wiki/Array_programming - 数组编程,或者称为“向量化”:
在计算机科学中,数组编程指的是允许将操作应用于整个值集的解决方案。这种解决方案通常在科学和工程领域中使用。
支持数组编程的现代编程语言(也称为向量或多维语言)已经专门设计用于将标量操作推广到向量、矩阵和更高维数组。这些语言包括APL、J、Fortran、MATLAB、Analytica、Octave、R、Cilk Plus、Julia、Perl Data Language(PDL)。在这些语言中,对整个数组进行操作的操作可以称为向量化操作,
1无论它是否在实现向量指令的向量处理器上执行。
在pandas中使用for循环真的很糟糕吗?我应该在什么时候关注它?
我的答案
pandas的iterrows方法是否存在性能问题?
这个答案
我在下面的评论中提到:
根据我的结果,我会说,以下是最佳方法的顺序:
1. 向量化,
2. 列表推导,
3. .itertuples(),
4. .apply(),
5. 原始的for循环,
6. .iterrows()。
我没有测试Cython。
pandas也是读取csv文件的首选。使用API来操作数据更加易于编程。 - F.S.