你可以编写自己的迭代器,实现namedtuple
from collections import namedtuple
def myiter(d, cols=None):
if cols is None:
v = d.values.tolist()
cols = d.columns.values.tolist()
else:
j = [d.columns.get_loc(c) for c in cols]
v = d.values[:, j].tolist()
n = namedtuple('MyTuple', cols)
for line in iter(v):
yield n(*line)
这与pd.DataFrame.itertuples是直接可比的。我的目标是以更高效的方式执行相同的任务。
对于给定的数据框,使用我的函数:
list(myiter(df))
[MyTuple(c1=10, c2=100), MyTuple(c1=11, c2=110), MyTuple(c1=12, c2=120)]
或者使用pd.DataFrame.itertuples:
list(df.itertuples(index=False))
[Pandas(c1=10, c2=100), Pandas(c1=11, c2=110), Pandas(c1=12, c2=120)]
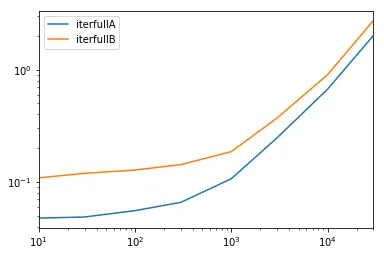
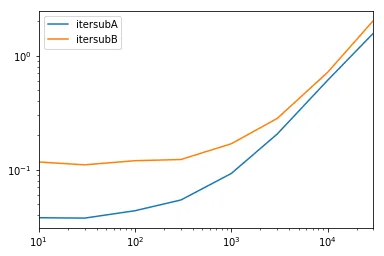
一项全面的测试
我们测试将所有列都可用并对列进行子集划分。
def iterfullA(d):
return list(myiter(d))
def iterfullB(d):
return list(d.itertuples(index=False))
def itersubA(d):
return list(myiter(d, ['col3', 'col4', 'col5', 'col6', 'col7']))
def itersubB(d):
return list(d[['col3', 'col4', 'col5', 'col6', 'col7']].itertuples(index=False))
res = pd.DataFrame(
index=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
columns='iterfullA iterfullB itersubA itersubB'.split(),
dtype=float
)
for i in res.index:
d = pd.DataFrame(np.random.randint(10, size=(i, 10))).add_prefix('col')
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit(stmt, setp, number=100)
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True);
pandas也是读取csv文件的首选。使用API来操作数据更加易于编程。 - F.S.