你可能已经注意到,你的单个组件无论是以加法还是几何方式都无法等于整体:
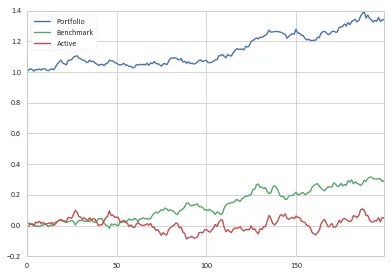
>>> cum.tail(1)
Portfolio Benchmark Active
199 1.342179 1.280958 1.025144
这总是一个令人困扰的情况,因为它表明您的模型可能发生了某种泄漏。
单期和多期归因混合始终是一个挑战。问题的一部分在于分析的目标,即您想要解释什么。
如果您正在查看累计回报,如上例所示,则可以按以下方式执行分析:
1.确保组合回报和基准回报都是超额回报,即减去相应期间的现金回报(例如,每日、每月等)。
2.假设您有一个富裕的叔叔借给您1亿美元来启动您的基金。现在您可以将您的投资组合视为三笔交易,其中包括一笔现金交易和两笔衍生品交易:
a) 将100百万美元投资在现金账户中,方便地赚取报价利率。
b) 进入100百万名义金额的股票掉期
c) 再次进入与零贝塔对冲基金的掉期交易,名义金额也为100百万。
我们方便地假设两笔掉期交易都由现金账户担保,并且没有交易成本(如果只有...!)。
第一天,股票指数上涨了略高于1%(扣除当日现金费用后的超额收益率为确切的1.00%)。然而,不相关的对冲基金却实现了-5%的超额回报。我们的基金现在是9600万美元。
第二天,我们如何再平衡?您的计算表明我们永远不会这样做。每个都是单独的组合,永远漂移...但是出于归因目的,我认为每天重新平衡是完全有道理的,即对两种策略分别分配100%。
由于这些只是名义敞口,拥有充足的现金抵押品,因此我们可以调整金额。因此,我们将重新平衡(零成本)而不是在第二天对股票指数暴露101m美元,对冲基金暴露95m美元,我们将调整为对每个策略暴露9600万美元。
您可能会问,在Pandas中如何工作?您已经计算出cum['Portfolio'],这是投资组合的累积超额增长因子(即扣除现金回报之后)。如果我们将当天的超额基准和主动回报应用于前一天的投资组合增长因子,则计算每日重新平衡的回报。
import numpy as np
import pandas as pd
np.random.seed(314)
df_returns = pd.DataFrame({
'Portfolio': np.random.randn(200) / 100 + 0.001,
'Benchmark': np.random.randn(200) / 100 + 0.001})
df_returns['Active'] = df.Portfolio - df.Benchmark
df_cum = pd.DataFrame()
df_cum['Portfolio'] = (1 + df_returns.Portfolio).cumprod()
portfolio_return_factors = pd.Series([1] + df_cum['Portfolio'].shift()[1:].tolist(), name='Portfolio_return_factor')
df_cum['Benchmark'] = (df_returns.Benchmark * portfolio_return_factors).cumsum()
df_cum['Active'] = (df_returns.Active * portfolio_return_factors).cumsum()
现在我们可以看到,主动回报加上基准回报加上初始现金等于投资组合的当前价值。
>>> df_cum.tail(3)[['Benchmark', 'Active', 'Portfolio']]
Benchmark Active Portfolio
197 0.303995 0.024725 1.328720
198 0.287709 0.051606 1.339315
199 0.292082 0.050098 1.342179
构造时,
df_cum['Portfolio'] = 1 + df_cum['Benchmark'] + df_cum['Active']。由于这种方法难以计算(没有Pandas!)和理解(大多数人不会了解名义敞口),行业惯例通常将主动回报定义为一段时间内收益的累积差异。例如,如果一个基金在一个月内上涨了5.0%,而市场下跌了1.0%,那么该月份的超额回报通常被定义为+6.0%。然而,这种简单的方法存在问题,因为由于复利和再平衡问题未被正确考虑进计算中,你的结果会随时间漂移。
因此,鉴于我们的df_cum.Active列,我们可以将最大回撤定义为:
drawdown = pd.Series(1 - (1 + df_cum.Active)/(1 + df_cum.Active.cummax()), name='Active Drawdown')
>>> df_cum.Active.plot(legend=True);drawdown.plot(legend=True)
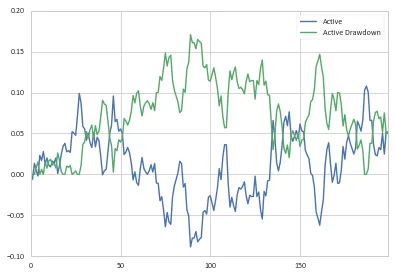
你可以像以前一样确定回撤的起点和终点。
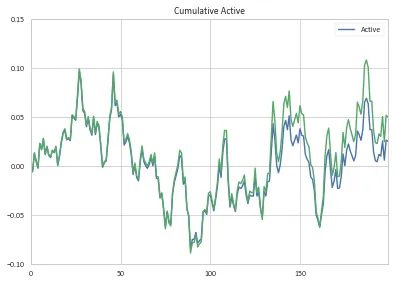
将我的累计主动回报贡献与你计算的金额进行比较,你会发现它们一开始很相似,但随着时间的推移会有所偏差(我的回报计算在绿色区域)。

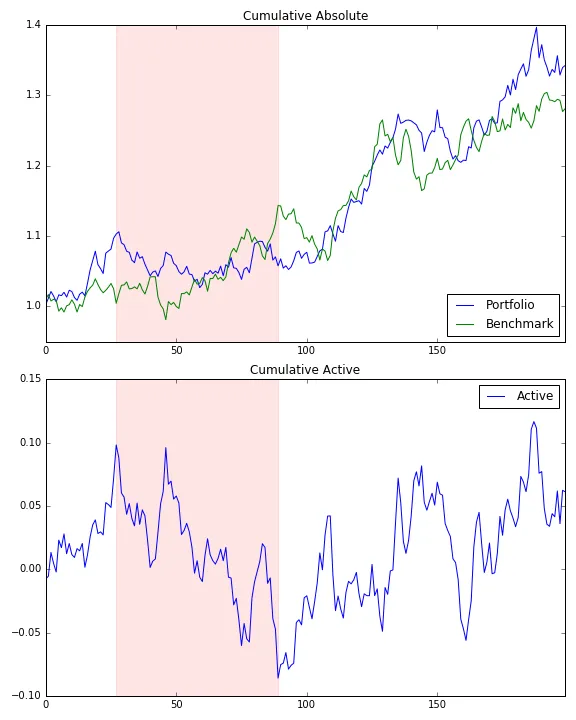
p = pd.Series([-0.1, -0.1, -0.1], name='p') b = pd.Series([-0.05, -0.05, -0.05], name='b') p = p.add(1).cumprod() b = b.add(1).cumprod() results = pd.concat([p, b], axis=1) results['cum diff'] = results['p'] - results['b'] results结果应为-0.128375。但是您的函数返回-0.0925。 - Pilgrim