最大回撤是量化金融中常用的风险指标,用于评估经历过的最大负回报。
最近,我对使用循环方法计算最大回撤所需的时间感到不耐烦。
def max_dd_loop(returns):
"""returns is assumed to be a pandas series"""
max_so_far = None
start, end = None, None
r = returns.add(1).cumprod()
for r_start in r.index:
for r_end in r.index:
if r_start < r_end:
current = r.ix[r_end] / r.ix[r_start] - 1
if (max_so_far is None) or (current < max_so_far):
max_so_far = current
start, end = r_start, r_end
return max_so_far, start, end
我熟悉一般观念,即矢量化的解决方案会更好。
问题是:
- 我能将此问题矢量化吗?
- 这个解决方案是什么样子的?
- 它有多大的益处?
编辑
我将Alexander的答案修改为以下函数:
def max_dd(returns):
"""Assumes returns is a pandas Series"""
r = returns.add(1).cumprod()
dd = r.div(r.cummax()).sub(1)
mdd = dd.min()
end = dd.argmin()
start = r.loc[:end].argmax()
return mdd, start, end
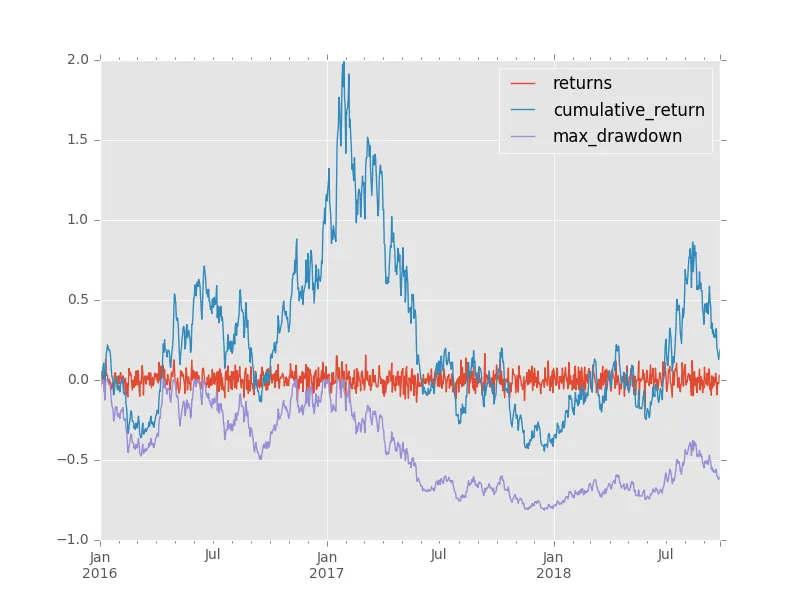
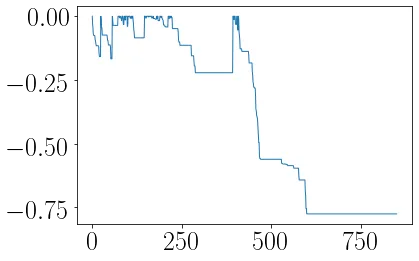
r.loc[:end].argmax()在这里会出问题。你需要使用r.loc[:end].sort_index(ascending=False).argmax()。如果你的序列中有多个零(即多个高水位标记),当前行将返回第一个而不是最后一个出现的零,并产生一个太早的开始日期。 - Brad Solomon.sort_index(ascending=False)来反转序列,则会错误地告诉您您的下降始于1月。我想这是解释问题,但按照这种方法,每次下降都会从第0个或第1个月开始吗?我从未见过将起始日期描述为这样。HWMs不必完全相同才能在您的下降序列中获得多个零。 - Brad Solomon