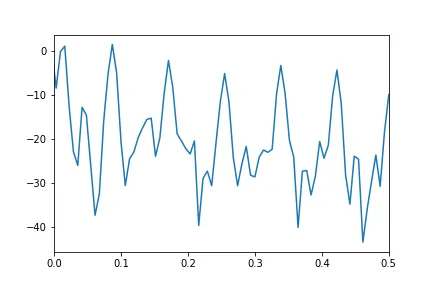
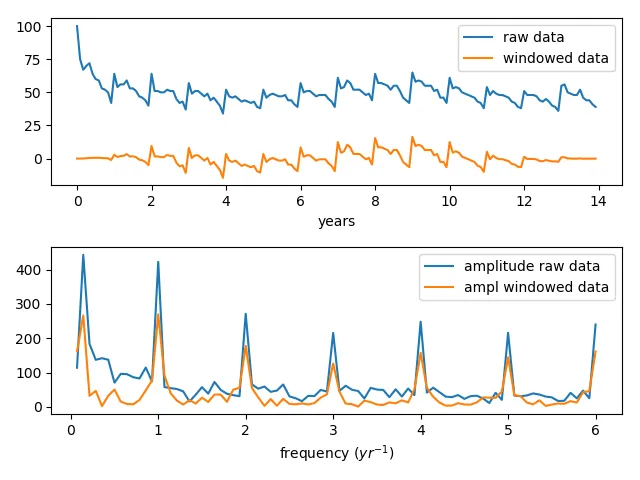
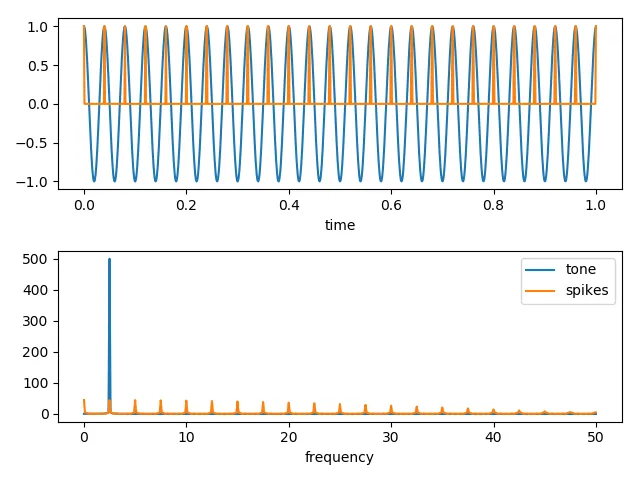
我正在尝试使用快速傅里叶变换评估Google趋势时间序列的幅度谱。如果您查看提供的此处的“饮食”数据,它显示出非常强的季节性模式。
然而,当我像这样应用FFT时(
我的幅度谱结果没有显示出任何主导峰。
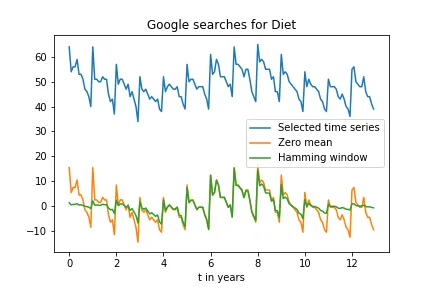
然而,当我像这样应用FFT时(
a_gtrend_ham是与Hamming窗口相乘的时间序列):import matplotlib.pyplot as plt
import numpy as np
from numpy.fft import fft, fftshift
import pandas as pd
gtrend = pd.read_csv('multiTimeline.csv',index_col=0)
gtrend.index = pd.to_datetime(gtrend.index, format='%Y-%m')
# Sampling rate
fs = 12 #Points per year
a_gtrend_orig = gtrend['diet: (Worldwide)']
N_gtrend_orig = len(a_gtrend_orig)
length_gtrend_orig = N_gtrend_orig / fs
t_gtrend_orig = np.linspace(0, length_gtrend_orig, num = N_gtrend_orig, endpoint = False)
a_gtrend_sel = a_gtrend_orig.loc['2005-01-01 00:00:00':'2017-12-01 00:00:00']
N_gtrend = len(a_gtrend_sel)
length_gtrend = N_gtrend / fs
t_gtrend = np.linspace(0, length_gtrend, num = N_gtrend, endpoint = False)
a_gtrend_zero_mean = a_gtrend_sel - np.mean(a_gtrend_sel)
ham = np.hamming(len(a_gtrend_zero_mean))
a_gtrend_ham = a_gtrend_zero_mean * ham
N_gtrend = len(a_gtrend_ham)
ampl_gtrend = 1/N_gtrend * abs(fft(a_gtrend_ham))
mag_gtrend = fftshift(ampl_gtrend)
freq_gtrend = np.linspace(-0.5, 0.5, len(ampl_gtrend))
response_gtrend = 20 * np.log10(mag_gtrend)
response_gtrend = np.clip(response_gtrend, -100, 100)
我的幅度谱结果没有显示出任何主导峰。