我有大约1000个不同的时间序列,对于每一个序列,我想自动确定是否存在季节性。
假设存在季节性,可以通过FFT或PSD确定周期性。
但是如何基于FFT或PSD自动判断信号中不存在季节性或周期性呢?
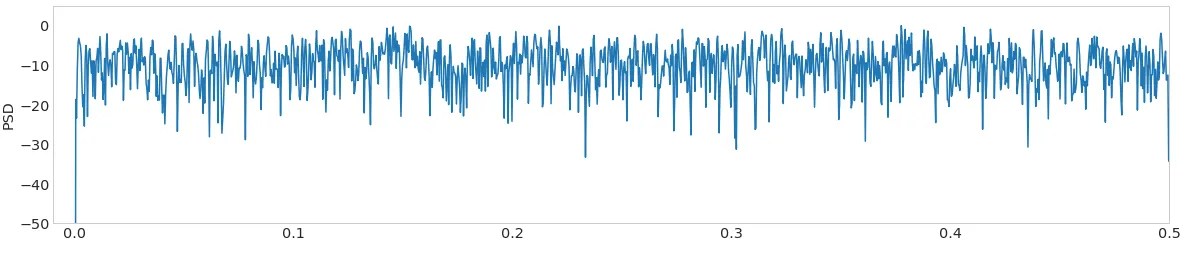
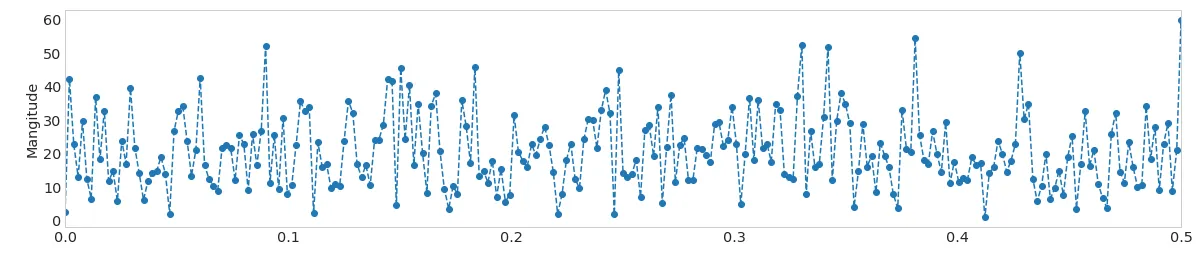
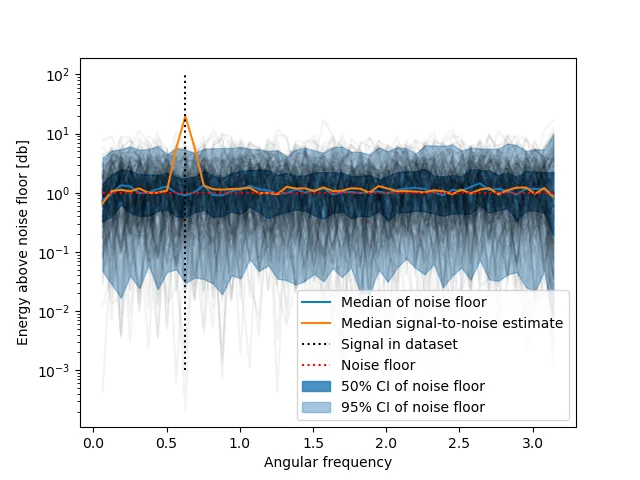
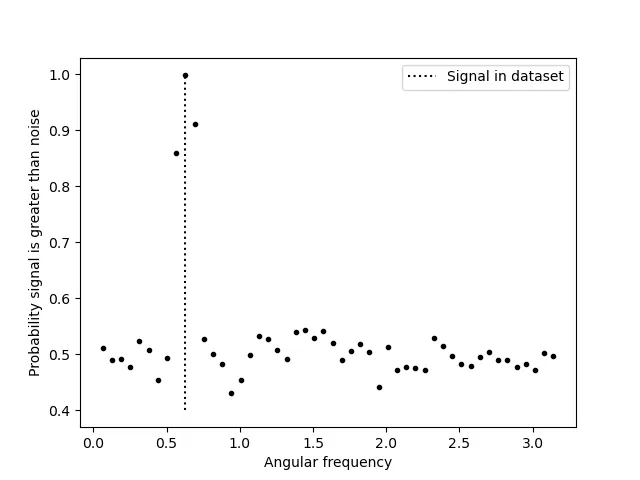
自动确定单个尖峰或高斯噪声是否基于时间序列的FFT或PSD具有季节性的方法是什么?有没有关于PSD幅度阈值的经验法则?峰值的突出程度?峰值高度?
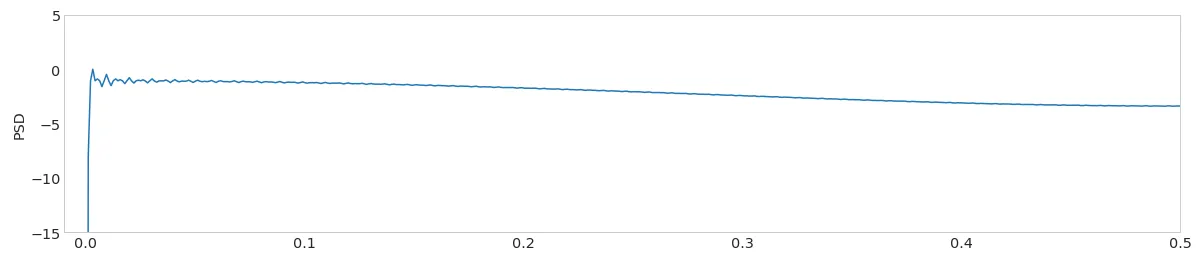
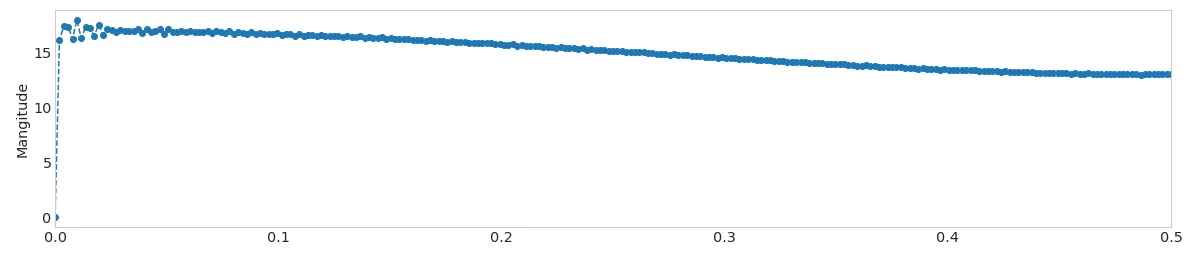
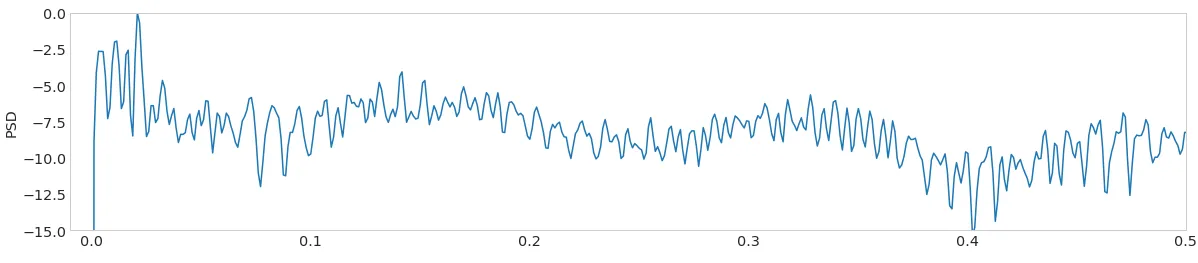
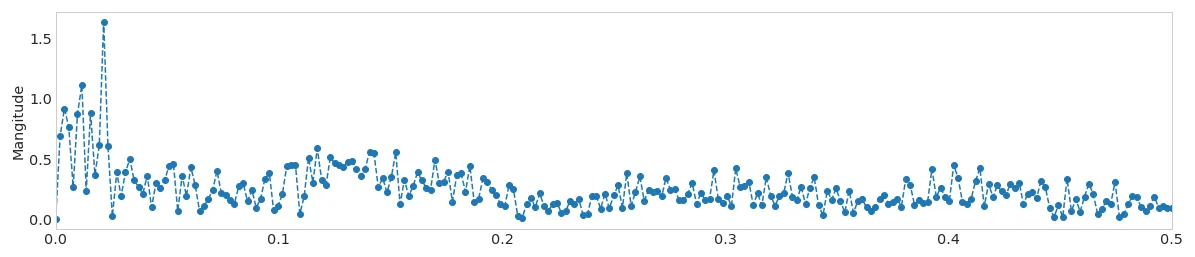
例如,单个尖峰的PSD图可能如下所示:
假设存在季节性,可以通过FFT或PSD确定周期性。
但是如何基于FFT或PSD自动判断信号中不存在季节性或周期性呢?
def psd_time_series(y):
yAC = np.correlate(Y-np.mean(Y), Y-np.mean(Y), mode='full')
yAC = yAC/np.max(yAC) # not necessary, but scales large values
fft_yAC= np.fft.fft(yAC)
freqs = np.arange(0,len(fft_yAC))/len(fft_yAC)
psd = 10*np.log10(np.abs(fft_yAC)/max(np.abs(fft_yAC))
return psd,freqs
def determine_if_seasonal(psd):
### part I need help with
def detect_seasonality(y):
psd,freqs = psd_time_series(y)
seasonality = ... #### do some check of PSD to determine if seasonal
if seasonality:
periodicity = round(1/freqs[psd.argsort()[::-1]][0])
else:
periodicity = None
return periodicity
自动确定单个尖峰或高斯噪声是否基于时间序列的FFT或PSD具有季节性的方法是什么?有没有关于PSD幅度阈值的经验法则?峰值的突出程度?峰值高度?
例如,单个尖峰的PSD图可能如下所示: