我将尝试使用Python的pandas库来确定两个时间序列重叠的百分比。由于数据是非同步的,因此每个数据点的时间不会对齐。这里有一个例子:
时间序列1:
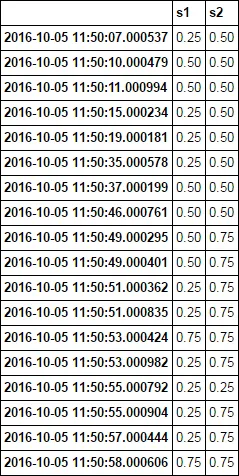
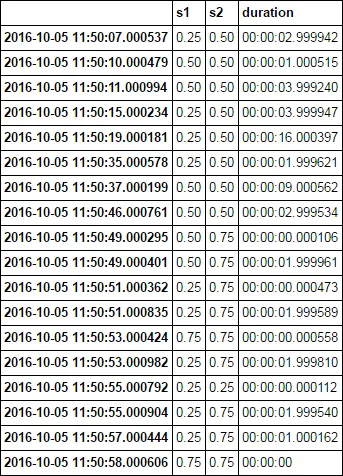
假设这个系列保持其价值直到下一次变化,最有效的方法是如何确定它们具有相同价值的时间百分比?让我们计算从11:50:07.000537开始到2016-10-05 11:50:57.000444结束之间这些系列重叠的时间。因为这段时间内两个系列都有数据,所以结果为0.75。他们同时存在的时间如下:
11:50:10.000479 - 11:50:15.000234 (两者的值均为0.5) 4.999755 秒
11:50:37.000199 - 11:50:49.000295 (两者的值均为0.5) 12.000096 秒
11:50:53.000424 - 11:50:53.000982 (两者的值均为0.75) 0.000558 秒
11:50:55.000792 - 11:50:55.000904 (两者的值均为0.25) 0.000112 秒
结果为(4.999755+12.000096+0.000558+0.000112) / 49.999907 = 34%
我的实际时间序列有更多的数据,如1000-10000条观测值,我需要运行更多的对比。我考虑过向前填充一个系列,然后只需比较行并将匹配总数除以总行数,但我认为这样做效率不高。
时间序列1:
2016-10-05 11:50:02.000734 0.50
2016-10-05 11:50:03.000033 0.25
2016-10-05 11:50:10.000479 0.50
2016-10-05 11:50:15.000234 0.25
2016-10-05 11:50:37.000199 0.50
2016-10-05 11:50:49.000401 0.50
2016-10-05 11:50:51.000362 0.25
2016-10-05 11:50:53.000424 0.75
2016-10-05 11:50:53.000982 0.25
2016-10-05 11:50:58.000606 0.75
时间序列 2
2016-10-05 11:50:07.000537 0.50
2016-10-05 11:50:11.000994 0.50
2016-10-05 11:50:19.000181 0.50
2016-10-05 11:50:35.000578 0.50
2016-10-05 11:50:46.000761 0.50
2016-10-05 11:50:49.000295 0.75
2016-10-05 11:50:51.000835 0.75
2016-10-05 11:50:55.000792 0.25
2016-10-05 11:50:55.000904 0.75
2016-10-05 11:50:57.000444 0.75
假设这个系列保持其价值直到下一次变化,最有效的方法是如何确定它们具有相同价值的时间百分比?让我们计算从11:50:07.000537开始到2016-10-05 11:50:57.000444结束之间这些系列重叠的时间。因为这段时间内两个系列都有数据,所以结果为0.75。他们同时存在的时间如下:
11:50:10.000479 - 11:50:15.000234 (两者的值均为0.5) 4.999755 秒
11:50:37.000199 - 11:50:49.000295 (两者的值均为0.5) 12.000096 秒
11:50:53.000424 - 11:50:53.000982 (两者的值均为0.75) 0.000558 秒
11:50:55.000792 - 11:50:55.000904 (两者的值均为0.25) 0.000112 秒
结果为(4.999755+12.000096+0.000558+0.000112) / 49.999907 = 34%
我的实际时间序列有更多的数据,如1000-10000条观测值,我需要运行更多的对比。我考虑过向前填充一个系列,然后只需比较行并将匹配总数除以总行数,但我认为这样做效率不高。