是否有适用于 Python 的 SciPy 函数、NumPy 函数或模块可以计算给定特定窗口的一维数组的滑动平均值?
移动平均或滑动平均
298
- Shejo284
2
1请注意,如果您在线构建数组,则问题陈述实际上变成了“如何最有效地维护一个向量,在末尾添加值并在开头弹出值”,因为您可以简单地维护一个平均值的单个累加器,每次输入一个值时添加新值并减去最旧的值,这在复杂度上是微不足道的。 - BjornW
以下除一条外,所有答案都没有回答问题:如何在添加新值时更新移动平均数,即“running”。我建议使用循环缓冲区,这样您就不必经常调整其大小,并且通过计算下一个平均值并了解上一个平均值和新值,可以更新下一个索引(模缓冲区大小)。简单的代数重排即可实现。 - D Left Adjoint to U
30个回答
367
更高效的解决方案可能包括scipy.ndimage.uniform_filter1d(请参见此答案)或使用较新的库,如talib的talib.MA。
使用
使用
np.convolve函数:np.convolve(x, np.ones(N)/N, mode='valid')
解释
滑动平均是数学运算卷积的一种情况。对于滑动平均,您沿着输入滑动一个窗口,并计算窗口内容的平均值。对于离散的一维信号,卷积是相同的操作,只是在计算时不是求平均值,而是计算任意线性组合,即将每个元素乘以相应的系数并将结果相加。这些系数,窗口中的每个位置都有一个,有时被称为卷积核。N个值的算术平均值是(x_1 + x_2 + ... + x_N) / N,因此相应的核是(1/N, 1/N, ..., 1/N),通过使用np.ones(N)/N就可以得到这个核。
边缘处理
np.convolve函数的mode参数指定如何处理边缘。我选择了valid模式,因为我认为这是大多数人对滑动平均的期望方式,但您可能有其他优先考虑。下面是一个说明不同模式之间差异的图表:
import numpy as np
import matplotlib.pyplot as plt
modes = ['full', 'same', 'valid']
for m in modes:
plt.plot(np.convolve(np.ones(200), np.ones(50)/50, mode=m));
plt.axis([-10, 251, -.1, 1.1]);
plt.legend(modes, loc='lower center');
plt.show()
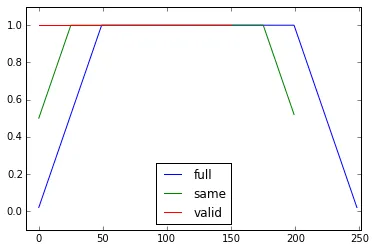
- lapis
4
10我喜欢这个解决方案,因为它简洁(只有一行),并且在numpy内部完成工作,相对来说也是高效的。但是Alleo的“高效解决方案”使用了
numpy.cumsum,具有更好的复杂度。 - Ulrich Stern2@denfromufa,我认为文档已经很好地覆盖了实现细节,并且还链接到了解释数学的维基百科。考虑到问题的重点,你认为这个答案需要复制那些内容吗? - lapis
对于绘图及相关任务,使用 None 值填充可能是有帮助的。我的(不是很美观但很简短)建议:
def moving_average(x, N, fill=True):
return np.concatenate([x for x in [
[None]*(N // 2 + N % 2)*fill,
np.convolve(x, np.ones((N,))/N, mode='valid'),
[None]*(N // 2)*fill,
] if len(x)])评论区里的代码看起来很丑陋,我不想再发一条新答案了,因为已经有太多了,不过你可以把它复制粘贴到你的 IDE 里。 - Chaoste1https://dev59.com/g2Yr5IYBdhLWcg3wYZKD#69808772 的速度是 uniform_filter1d 的两倍,误差相同。 - Gideon Kogan
184
高效的解决方案
卷积比直接计算更好,但(我猜)它使用FFT,因此速度相对较慢。然而,特别适用于计算运行平均值的以下方法效果不错。
def running_mean(x, N):
cumsum = numpy.cumsum(numpy.insert(x, 0, 0))
return (cumsum[N:] - cumsum[:-N]) / float(N)
检查代码
In[3]: x = numpy.random.random(100000)
In[4]: N = 1000
In[5]: %timeit result1 = numpy.convolve(x, numpy.ones((N,))/N, mode='valid')
10 loops, best of 3: 41.4 ms per loop
In[6]: %timeit result2 = running_mean(x, N)
1000 loops, best of 3: 1.04 ms per loop
请注意,numpy.allclose(result1, result2) 的返回值为 True,表示两种方法是等价的。
警告:虽然使用 cumsum 方法速度更快,但会增加浮点误差,可能导致结果无效/不正确/不可接受。
# demonstrate loss of precision with only 100,000 points
np.random.seed(42)
x = np.random.randn(100000)+1e6
y1 = running_mean_convolve(x, 10)
y2 = running_mean_cumsum(x, 10)
assert np.allclose(y1, y2, rtol=1e-12, atol=0)
- 累积的点数越多,浮点误差就越大(所以1e5个点是可以察觉的,1e6个点更明显,超过1e6后可能需要重置累加器)。
- 你可以使用
np.longdouble来作弊,但对于较大数量的点数(大约>1e5,具体取决于数据),浮点误差仍然会变得显著。 - 您可以绘制误差曲线并观察它相对快速地增加。
- 卷积解决方案较慢,但不会出现这种浮点精度损失。
- uniform_filter1d解决方案比此cumsum解决方案更快,并且不会出现这种浮点精度损失。
- Alleo
13
3这种方法不处理数组的边缘,对吗? - JoVe
9好的解决方案,但需要注意对于大数组可能会存在数值误差,因为在数组末尾时,你可能会相减两个较大的数字来获得一个较小的结果。 - Bas Swinckels
2这里使用了整数除法而不是浮点数除法:
running_mean([1,2,3], 2) 的结果为 array([1, 2])。将 x 替换为 [float(value) for value in x] 即可解决问题。 - ChrisW6如果
x包含浮点数,此解决方案的数值稳定性可能会成为问题。例如:running_mean(np.arange(int(1e7))[::-1] + 0.2, 1)[-1] - 0.2返回0.003125,而我们期望得到的是0.0。更多信息请参阅https://en.wikipedia.org/wiki/Loss_of_significance。 - Milan显示剩余8条评论
101
你可以使用 scipy.ndimage.uniform_filter1d:
import numpy as np
from scipy.ndimage import uniform_filter1d
N = 1000
x = np.random.random(100000)
y = uniform_filter1d(x, size=N)
uniform_filter1d:
- 输出与numpy数组具有相同的形状(即点数)
- 允许使用多种方式处理边界,其中
'reflect'是默认设置,但在我的情况下,我更喜欢使用'nearest'
该方法速度较快(几乎比np.convolve快50倍,比上述cumsum方法快2-5倍):
%timeit y1 = np.convolve(x, np.ones((N,))/N, mode='same')
100 loops, best of 3: 9.28 ms per loop
%timeit y2 = uniform_filter1d(x, size=N)
10000 loops, best of 3: 191 µs per loop
这里有3个函数,可以让您比较不同实现的错误/速度:
from __future__ import division
import numpy as np
import scipy.ndimage as ndi
def running_mean_convolve(x, N):
return np.convolve(x, np.ones(N) / float(N), 'valid')
def running_mean_cumsum(x, N):
cumsum = np.cumsum(np.insert(x, 0, 0))
return (cumsum[N:] - cumsum[:-N]) / float(N)
def running_mean_uniform_filter1d(x, N):
return ndi.uniform_filter1d(x, N, mode='constant', origin=-(N//2))[:-(N-1)]
- moi
3
2这是唯一一个似乎考虑到边界问题的答案(这个问题非常重要,特别是在绘图时)。谢谢! - Gabriel
2我对
uniform_filter1d、np.convolve和矩形以及np.cumsum后跟np.subtract进行了分析。我的结果是:(1)卷积最慢。(2)cumsum/subtract大约快20-30倍。(3)uniform_filter1d比cumsum/subtract快2-3倍。胜者绝对是uniform_filter1d。 - Trevor Boyd Smith2使用
uniform_filter1d 比 cumsum 解决方案更快(大约快2-5倍)。而且,与 cumsum 解决方案相比,uniform_filter1d 不会出现大量浮点误差。 (参考链接:https://dev59.com/g2Yr5IYBdhLWcg3wYZKD#BLOiEYcBWogLw_1bovvC) - Trevor Boyd Smith98
更新:下面的示例显示了旧版本的 pandas.rolling_mean 函数,该函数已在最新版本的 pandas 中被删除。现代等效的函数调用将使用 pandas.Series.rolling:
In [8]: pd.Series(x).rolling(window=N).mean().iloc[N-1:].values
Out[8]:
array([ 0.49815397, 0.49844183, 0.49840518, ..., 0.49488191,
0.49456679, 0.49427121])
Pandas比NumPy或SciPy更适合这个任务。它的函数rolling_mean可以方便地完成此任务,且当输入为数组时,它还会返回一个NumPy数组。
使用任何自定义的纯Python实现都很难在性能上超越rolling_mean。以下是性能示例与两种提议的解决方案进行比较:
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: def running_mean(x, N):
...: cumsum = np.cumsum(np.insert(x, 0, 0))
...: return (cumsum[N:] - cumsum[:-N]) / N
...:
In [4]: x = np.random.random(100000)
In [5]: N = 1000
In [6]: %timeit np.convolve(x, np.ones((N,))/N, mode='valid')
10 loops, best of 3: 172 ms per loop
In [7]: %timeit running_mean(x, N)
100 loops, best of 3: 6.72 ms per loop
In [8]: %timeit pd.rolling_mean(x, N)[N-1:]
100 loops, best of 3: 4.74 ms per loop
In [9]: np.allclose(pd.rolling_mean(x, N)[N-1:], running_mean(x, N))
Out[9]: True
还有一些不错的选项来处理边缘值。
- jasaarim
6
6Pandas 的 rolling_mean 是一个很好的工具,但已被弃用于 ndarrays。在未来的 Pandas 版本中,它只能用于 Pandas series。那么,对于非 Pandas 数组数据,我们现在可以转向哪里呢? - Mike
5@Mike rolling_mean()已被弃用,但现在您可以单独使用rolling和mean函数:
df.rolling(windowsize).mean()。这个方法非常快速。对于一个有6,000行的数据系列,%timeit test1.rolling(20).mean() 返回 1000 loops, best of 3: 1.16 ms per loop. - Vlox8
df.rolling() 目前已经能够正常运行,但问题是未来即使使用这种形式也将不支持 ndarrays。为了使用它,我们必须先将数据加载到 Pandas Dataframe 中。我希望看到这个函数被添加到 numpy 或 scipy.signal 中。 - Mike1@Mike 完全同意。我特别苦恼于如何匹配pandas .ewm().mean()的速度,以适应我的自定义数组(而不是必须先将它们加载到df中)。我的意思是,虽然速度很快,但频繁地在数据帧之间移动感觉有点笨拙。 - Vlox
uniform_filter1d检查后速度提高了3倍。 - Oren
52
您可以使用以下公式来计算移动平均值:
import numpy as np
def runningMean(x, N):
y = np.zeros((len(x),))
for ctr in range(len(x)):
y[ctr] = np.sum(x[ctr:(ctr+N)])
return y/N
但这很慢。
幸运的是,numpy 包含一个 convolve 函数,我们可以用它来加速处理。运行均值等同于将 x 与一个长度为 N,所有元素都相等于 1/N 的向量进行卷积。Numpy 的 convolve 实现包括了起始瞬态,因此你必须移除前 N-1 个点:
def runningMeanFast(x, N):
return np.convolve(x, np.ones((N,))/N)[(N-1):]
在我的电脑上,快速版本比慢速版本快20-30倍,具体取决于输入向量的长度和平均窗口的大小。
请注意,convolve函数确实包括一个'same'模式,它似乎可以解决起始瞬态问题,但它将其分为开头和结尾两部分。
- mtrw
5
请注意,删除前N-1个点仍会在最后几个点留下边界效应。解决此问题的更简单方法是在
convolve中使用mode ='valid',它不需要任何后处理。 - lapis1@Psycho -
mode='valid'会从两端移除瞬态,对吗?如果len(x)=10且N=4,对于运行平均值,我想要10个结果,但是valid只返回7个。 - mtrw1它从末尾删除瞬态,而开头没有瞬态。好吧,我想这是一个优先级的问题,我不需要在数据中得到一个趋近于零的斜率来换取相同数量的结果。顺便说一句,这里有一个命令可以显示模式之间的差异:
modes = ('full', 'same', 'valid'); [plot(convolve(ones((200,)), ones((50,))/50, mode=m)) for m in modes]; axis([-10, 251, -.1, 1.1]); legend(modes, loc='lower center')(导入pyplot和numpy)。 - lapisrunningMean 当你在数组的右侧使用 x[ctr:(ctr+N)] 时,是否会出现用零进行平均的副作用。 - mrgloomrunningMeanFast 也存在这个边界效应问题。 - mrgloom30
以下代码是一种快速简洁的解决方案,只需要一个循环即可完成整个过程,而且不需要任何依赖。
mylist = [1, 2, 3, 4, 5, 6, 7]
N = 3
cumsum, moving_aves = [0], []
for i, x in enumerate(mylist, 1):
cumsum.append(cumsum[i-1] + x)
if i>=N:
moving_ave = (cumsum[i] - cumsum[i-N])/N
#can do stuff with moving_ave here
moving_aves.append(moving_ave)
- Aikude
3
95快?!这个解决方案比使用Numpy的解决方案慢了数个数量级。 - Bart
6虽然这种本地解决方案很棒,但OP要求使用numpy/scipy函数-假定它们会更快。 - Demis
1但它不需要100+MB的框架,非常适合SBC。 - Vincent Alex
28
一个用于计算的Python模块
在Tradewave.net的测试中,TA-lib总是获胜:
import talib as ta
import numpy as np
import pandas as pd
import scipy
from scipy import signal
import time as t
PAIR = info.primary_pair
PERIOD = 30
def initialize():
storage.reset()
storage.elapsed = storage.get('elapsed', [0,0,0,0,0,0])
def cumsum_sma(array, period):
ret = np.cumsum(array, dtype=float)
ret[period:] = ret[period:] - ret[:-period]
return ret[period - 1:] / period
def pandas_sma(array, period):
return pd.rolling_mean(array, period)
def api_sma(array, period):
# this method is native to Tradewave and does NOT return an array
return (data[PAIR].ma(PERIOD))
def talib_sma(array, period):
return ta.MA(array, period)
def convolve_sma(array, period):
return np.convolve(array, np.ones((period,))/period, mode='valid')
def fftconvolve_sma(array, period):
return scipy.signal.fftconvolve(
array, np.ones((period,))/period, mode='valid')
def tick():
close = data[PAIR].warmup_period('close')
t1 = t.time()
sma_api = api_sma(close, PERIOD)
t2 = t.time()
sma_cumsum = cumsum_sma(close, PERIOD)
t3 = t.time()
sma_pandas = pandas_sma(close, PERIOD)
t4 = t.time()
sma_talib = talib_sma(close, PERIOD)
t5 = t.time()
sma_convolve = convolve_sma(close, PERIOD)
t6 = t.time()
sma_fftconvolve = fftconvolve_sma(close, PERIOD)
t7 = t.time()
storage.elapsed[-1] = storage.elapsed[-1] + t2-t1
storage.elapsed[-2] = storage.elapsed[-2] + t3-t2
storage.elapsed[-3] = storage.elapsed[-3] + t4-t3
storage.elapsed[-4] = storage.elapsed[-4] + t5-t4
storage.elapsed[-5] = storage.elapsed[-5] + t6-t5
storage.elapsed[-6] = storage.elapsed[-6] + t7-t6
plot('sma_api', sma_api)
plot('sma_cumsum', sma_cumsum[-5])
plot('sma_pandas', sma_pandas[-10])
plot('sma_talib', sma_talib[-15])
plot('sma_convolve', sma_convolve[-20])
plot('sma_fftconvolve', sma_fftconvolve[-25])
def stop():
log('ticks....: %s' % info.max_ticks)
log('api......: %.5f' % storage.elapsed[-1])
log('cumsum...: %.5f' % storage.elapsed[-2])
log('pandas...: %.5f' % storage.elapsed[-3])
log('talib....: %.5f' % storage.elapsed[-4])
log('convolve.: %.5f' % storage.elapsed[-5])
log('fft......: %.5f' % storage.elapsed[-6])
结果:
[2015-01-31 23:00:00] ticks....: 744
[2015-01-31 23:00:00] api......: 0.16445
[2015-01-31 23:00:00] cumsum...: 0.03189
[2015-01-31 23:00:00] pandas...: 0.03677
[2015-01-31 23:00:00] talib....: 0.00700 # <<< Winner!
[2015-01-31 23:00:00] convolve.: 0.04871
[2015-01-31 23:00:00] fft......: 0.22306
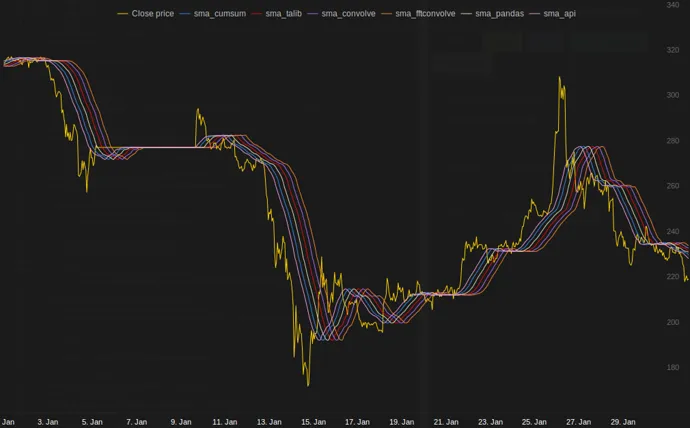
- litepresence
4
NameError: name 'info' is not defined。我遇到了这个错误,先生。 - Md. Rezwanul Haque
3看起来你的时间序列在平滑后发生了位移,这是想要的效果吗? - mrgloom
1@mrgloom 是的,出于可视化的目的;否则它们将出现在图表上的一条线上;Md. Rezwanul Haque 你可以删除所有与PAIR和info有关的引用;这些都是为了已停用的tradewave.net而设计的内部沙盒方法。 - litepresence
你能添加scipy.ndimage uniform_filter1d吗?谢谢! - Oren
24
如需立即可用的解决方案,请参见https://scipy-cookbook.readthedocs.io/items/SignalSmooth.html。
该方案提供了使用flat窗口类型的移动平均值。请注意,这比简单的自行卷积方法要复杂一些,因为它试图通过反射来处理数据开头和结尾的问题(在您的情况下可能有用,也可能无用...)。
首先,您可以尝试:
a = np.random.random(100)
plt.plot(a)
b = smooth(a, window='flat')
plt.plot(b)
- Hansemann
4
1这种方法依赖于
numpy.convolve,唯一的区别在于改变序列。 - Alleo14当输入和输出的信号本质相同(例如,都是时间信号),但信号处理函数返回不同形状的输出信号时,我总是感到烦恼。这会破坏与相关独立变量(如时间、频率)的对应关系,使得绘图或比较不是一个直观的过程……无论如何,如果你有同样的感受,你可能想要更改建议函数的最后几行为:
y=np.convolve(w/w.sum(),s,mode='same');
return y[window_len-1:-(window_len-1)] - Christian O'Reilly@ChristianO'Reilly,你应该将它作为一个单独的答案发布——这正是我正在寻找的,因为我确实有另外两个数组需要匹配平滑数据的长度,以便进行绘图等操作。我想知道你是如何做到的——
w是窗口大小,s是数据吗? - Demis@Demis 很高兴评论有所帮助。在这里可以找到有关numpy convolve函数的更多信息:https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.convolve.html 卷积函数(https://en.wikipedia.org/wiki/Convolution)将两个信号相互卷积。在这种情况下,它将您的信号(s)与归一化(即单位面积)窗口(w/w.sum())进行卷积。 - Christian O'Reilly
17
我知道这是一个旧问题,但这里有一个解决方案,它不使用任何额外的数据结构或库。它在输入列表的元素数量上是线性的,我无法想到其他更有效的方法(实际上,如果有人知道一种更好的分配结果的方法,请告诉我)。
注意:使用numpy数组而不是列表会快得多,但我想消除所有依赖性。也可以通过多线程执行来提高性能。
该函数假设输入列表是一维的,所以请小心。
### Running mean/Moving average
def running_mean(l, N):
sum = 0
result = list( 0 for x in l)
for i in range( 0, N ):
sum = sum + l[i]
result[i] = sum / (i+1)
for i in range( N, len(l) ):
sum = sum - l[i-N] + l[i]
result[i] = sum / N
return result
示例
假设我们有一个列表data = [1,2,3,4,5,6],我们想要对其进行周期为3的滚动平均值计算,并且您还希望输出列表与输入列表大小相同(这通常是最常见的情况)。
第一个元素的索引为0,因此滚动平均应该计算索引为-2、-1和0的元素。显然,我们没有data[-2]和data[-1](除非您想使用特殊的边界条件),因此我们假设这些元素为0。这相当于对列表进行零填充,除了我们实际上不填充它,只是跟踪需要填充的索引(从0到N-1)。
因此,对于前N个元素,我们只需将元素累加到累加器中。
result[0] = (0 + 0 + 1) / 3 = 0.333 == (sum + 1) / 3
result[1] = (0 + 1 + 2) / 3 = 1 == (sum + 2) / 3
result[2] = (1 + 2 + 3) / 3 = 2 == (sum + 3) / 3
从第N+1个元素开始,简单的累加方法不再适用。我们期望result[3]=(2+3+4)/3=3,但这与(sum+4)/3=3.333不同。
计算正确值的方法是从sum+4中减去data[0]=1,因此得到sum+4-1=9。
这是因为目前sum=data[0]+data[1]+data[2],但对于每个i >= N也是如此,因为在减法之前,sum=data[i-N]+...+data[i-2]+data[i-1]。
- NeXuS
15
我认为可以通过使用bottleneck优雅地解决这个问题。
以下是基本示例:
import numpy as np
import bottleneck as bn
a = np.random.randint(4, 1000, size=100)
mm = bn.move_mean(a, window=5, min_count=1)
"mm" 是 "a" 的移动平均值。
"window" 是考虑移动平均的最大条目数。
"min_count" 是考虑移动平均的最小条目数(例如,对于前几个元素或如果数组具有nan值)。
好的部分是Bottleneck帮助处理nan值并且也非常高效。
- Anthony Anyanwu
1
这个库非常快。纯Python的移动平均函数很慢。Bootleneck是一个PyData库,我认为它很稳定,并且可以获得Python社区的持续支持,那为什么不使用它呢? - GoingMyWay
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接