我想从一个附加的图片(png文件)中读取一列数字。
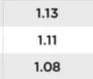
我的代码是:
import cv2
import pytesseract
import os
img = cv2.imread(os.path.join(image_path, image_name), 0)
config= "-c
tessedit_char_whitelist=01234567890.:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
pytesseract.image_to_string(img, config=config)
这段代码输出字符串:'n113\nun\n1.08'。我们可以看出,有两个问题:
- 它无法识别1.13中的小数点(参见附图)。
- 它完全无法读取1.11(参见附图)。它只返回“nun”。
最好的祝愿

(5,5)以帮助平滑图像并在阈值化之前去除微小的点。这只是典型的核大小。其他可行的大小有(3,3)或(7,7),这取决于图像和存在噪声的数量。 - nathancy