我使用代码来定位文本框并在它们周围创建矩形。这使我能够在图像中重新构建表结构周围的网格。
然而,即使文本框的检测效果非常好,如果我尝试定义每个矩形中存在的字符,pytesseract 也不能很好地识别它们,也不能找到原始文本。
以下是我的Python代码:
import os
import cv2
import imutils
import argparse
import numpy as np
import pytesseract
# This only works if there's only one table on a page
# Important parameters:
# - morph_size
# - min_text_height_limit
# - max_text_height_limit
# - cell_threshold
# - min_columns
def pre_process_image(img, save_in_file, morph_size=(8, 8)):
# get rid of the color
pre = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
def img_estim(img, threshold=127):
is_dark = np.mean(img) < threshold
return True if is_dark else False
# Negative
if img_estim(pre):
print("non")
pre = cv2.bitwise_not(pre)
# Contrast & Brightness control
contrast = 2.0 #0 to 3
brightness = 0 #0 to 100
for y in range(pre.shape[0]):
for x in range(pre.shape[1]):
pre[y,x] = np.clip(contrast*pre[y,x] + brightness, 0, 255)
# Otsu threshold
pre = cv2.threshold(pre, 250, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# dilate the text to make it solid spot
cpy = pre.copy()
struct = cv2.getStructuringElement(cv2.MORPH_RECT, morph_size)
cpy = cv2.dilate(~cpy, struct, anchor=(-1, -1), iterations=1)
pre = ~cpy
if save_in_file is not None:
cv2.imwrite(save_in_file, pre)
return pre
def find_text_boxes(pre, min_text_height_limit=15, max_text_height_limit=40):
# Looking for the text spots contours
# OpenCV 3
# img, contours, hierarchy = cv2.findContours(pre, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# OpenCV 4
contours, hierarchy = cv2.findContours(pre, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# Getting the texts bounding boxes based on the text size assumptions
boxes = []
for contour in contours:
box = cv2.boundingRect(contour)
h = box[3]
if min_text_height_limit < h < max_text_height_limit:
boxes.append(box)
return boxes
def find_table_in_boxes(boxes, cell_threshold=10, min_columns=2):
rows = {}
cols = {}
# Clustering the bounding boxes by their positions
for box in boxes:
(x, y, w, h) = box
col_key = x // cell_threshold
row_key = y // cell_threshold
cols[row_key] = [box] if col_key not in cols else cols[col_key] + [box]
rows[row_key] = [box] if row_key not in rows else rows[row_key] + [box]
# Filtering out the clusters having less than 2 cols
table_cells = list(filter(lambda r: len(r) >= min_columns, rows.values()))
# Sorting the row cells by x coord
table_cells = [list(sorted(tb)) for tb in table_cells]
# Sorting rows by the y coord
table_cells = list(sorted(table_cells, key=lambda r: r[0][1]))
return table_cells
def build_lines(table_cells):
if table_cells is None or len(table_cells) <= 0:
return [], []
max_last_col_width_row = max(table_cells, key=lambda b: b[-1][2])
max_x = max_last_col_width_row[-1][0] + max_last_col_width_row[-1][2]
max_last_row_height_box = max(table_cells[-1], key=lambda b: b[3])
max_y = max_last_row_height_box[1] + max_last_row_height_box[3]
hor_lines = []
ver_lines = []
for box in table_cells:
x = box[0][0]
y = box[0][1]
hor_lines.append((x, y, max_x, y))
for box in table_cells[0]:
x = box[0]
y = box[1]
ver_lines.append((x, y, x, max_y))
(x, y, w, h) = table_cells[0][-1]
ver_lines.append((max_x, y, max_x, max_y))
(x, y, w, h) = table_cells[0][0]
hor_lines.append((x, max_y, max_x, max_y))
return hor_lines, ver_lines
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
# ap.add_argument("-east", "--east", type=str,
# help="path to input EAST text detector")
args = vars(ap.parse_args())
in_file = os.path.join("images", args["image"])
pre_file = os.path.join("images", "pre.png")
out_file = os.path.join("images", "out.png")
img = cv2.imread(os.path.join(in_file))
top, bottom, left, right = [25]*4
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_REPLICATE)
orig = img.copy()
pre_processed = pre_process_image(img, pre_file)
text_boxes = find_text_boxes(pre_processed)
cells = find_table_in_boxes(text_boxes)
hor_lines, ver_lines = build_lines(cells)
# (H, W) = img.shape[:2]
# net = cv2.dnn.readNet(args["east"])
# blob = cv2.dnn.blobFromImage(img, 1.0, (W, H),(123.68, 116.78, 103.94), swapRB=True, crop=False)
# net.setInput(blob)
# Visualize the result
vis = img.copy()
results = []
for box in text_boxes:
(x, y, w, h) = box
startX = x -2
startY = y -2
endX = x + w
endY = y + h
cv2.rectangle(vis, (startX, startY), (endX, endY), (0, 255, 0), 1)
roi=orig[startX:endX,startY:endY]
config = ("-l eng --psm 6")
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
text = pytesseract.image_to_string(roi,config=config )
results.append(((startX, startY, (endX), (endY)), text))
results = sorted(results, key=lambda r:r[0][1])
output = orig.copy()
for ((startX, startY, endX, endY), text) in results:
print("{}\n".format(text))
text = "".join([c if ord(c) < 128 else "" for c in text]).strip()
cv2.rectangle(output, (startX, startY), (endX, endY),(0, 0, 255), 1)
cv2.putText(output, text, (startX, startY - 20),cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
# for line in hor_lines:
# [x1, y1, x2, y2] = line
# cv2.line(vis, (x1, y1), (x2, y2), (0, 0, 255), 1)
# for line in ver_lines:
# [x1, y1, x2, y2] = line
# cv2.line(vis, (x1, y1), (x2, y2), (0, 0, 255), 1)
cv2.imwrite(out_file, vis)
cv2.imshow("Text Detection", output)
cv2.waitKey(0)
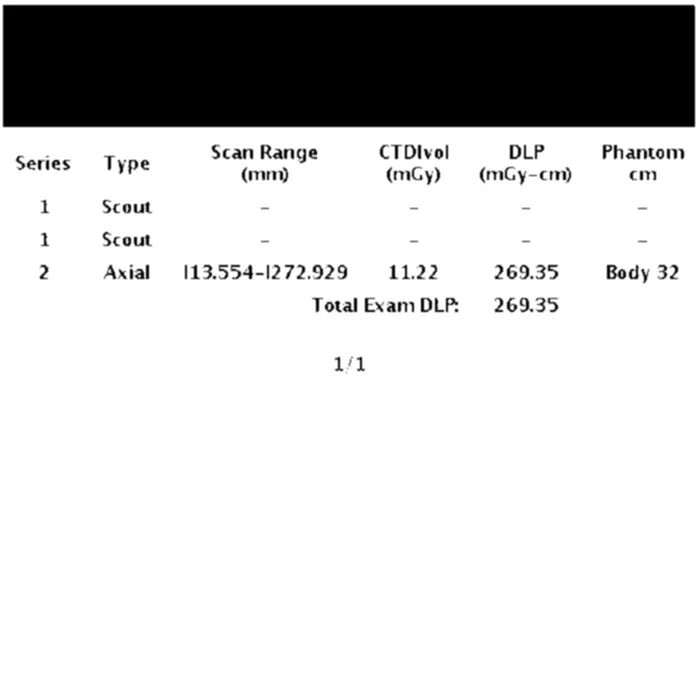
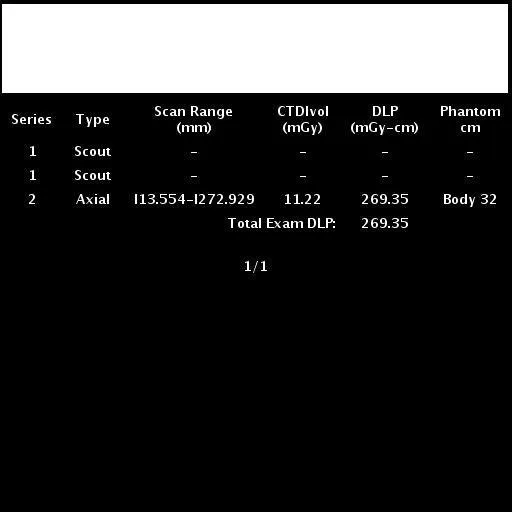
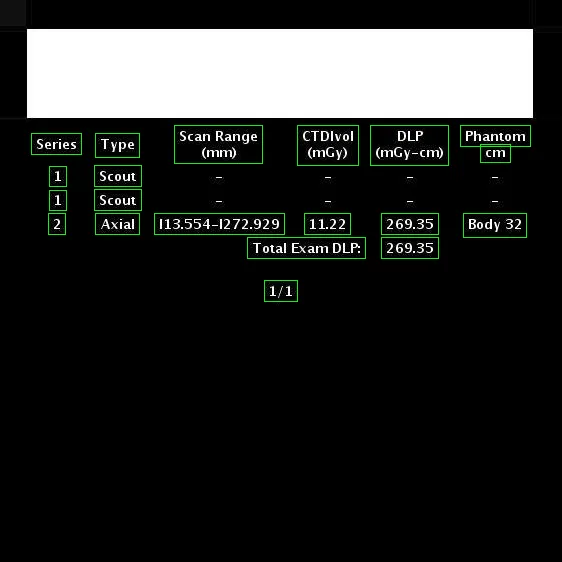
初始图像: 初始图像 经过文本轮廓检测处理的预处理图像,以定义矩形的尺寸: 经过文本轮廓检测处理的预处理图像,以定义矩形的尺寸 最终图像: 最终图像 OCR识别结果:
"
a ra at
12
1 "
感谢您的帮助,希望我的描述足够清晰。
{kind=link}
{kind=link}
{kind=link}