我正在尝试让PyTesseract OCR从这张简单且裁剪得很好的图片中读取数字,但由于某些原因它无法做到。
from PIL import Image
import pytesseract as p
def obtain_balance(a):
im = Image.open(a)
width,height = im.size
a = 300*5 - 120
# print(width,height)
left = 155+a
top = 5
right = 360+a
bottom = 120
m1 = im.crop((left, top, right, bottom))
text = p.image_to_string(m1,lang='eng',config='--psm 13 --oem 3 -c tessedit_char_whitelist=0123456789').split()
print(text)
m1.show()
return text
obtain_balance('cur.jpg')
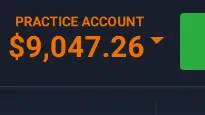
输出:
[]
