这里提供了一个使用OpenCV和Pytesseract OCR的简单方法。在对图像进行OCR之前,重要的是对图像进行预处理。我们的想法是获取一个处理后的图像,其中要提取的文本为黑色,背景为白色。为此,我们可以将其转换为灰度,然后使用cv2.filter2D() 应用锐化核来增强模糊部分。一个通用的锐化核如下所示:
[[-1,-1,-1], [-1,9,-1], [-1,-1,-1]]
你可以在这里找到其他的内核变化。根据图片,你可以调整过滤器的强度。从这里我们使用Otsu's threshold获取一个二进制图像,然后使用--psm 6配置选项进行文本提取以假设单一均匀文本块。查看这里获取更多OCR配置选项。
下面是图像处理管道的可视化:
输入图像

转换为灰度图->应用锐化滤波器

Otsu's threshold
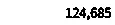
Pytesseract OCR的结果
124,685
代码
import cv2
import numpy as np
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
sharpen_kernel = np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])
sharpen = cv2.filter2D(gray, -1, sharpen_kernel)
thresh = cv2.threshold(sharpen, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
data = pytesseract.image_to_string(thresh, lang='eng', config='--psm 6')
print(data)
cv2.imshow('sharpen', sharpen)
cv2.imshow('thresh', thresh)
cv2.waitKey()
