在使用numpy将文件导入后,当我使用以下代码分离x_values和y_values时:
import pandas as pd
from sklearn import linear_model
from matplotlib import pyplot
import numpy as np
#read data
dataframe = pd.read_csv('challenge_dataset.txt')
dataframe.columns=['Brain','Body']
x_values=np.array(dataframe['Brain'],dtype=np.float64).reshape(1,-1)
y_values=np.array(dataframe['Body'],dtype=np.float64).reshape(1,-1)
#train model on data
body_reg = linear_model.LinearRegression()
body_reg.fit(x_values, y_values)
prediction=body_reg.predict(x_values)
print(prediction)
#visualize results
pyplot.scatter(x_values, y_values)
pyplot.plot(x_values,prediction)
pyplot.show()
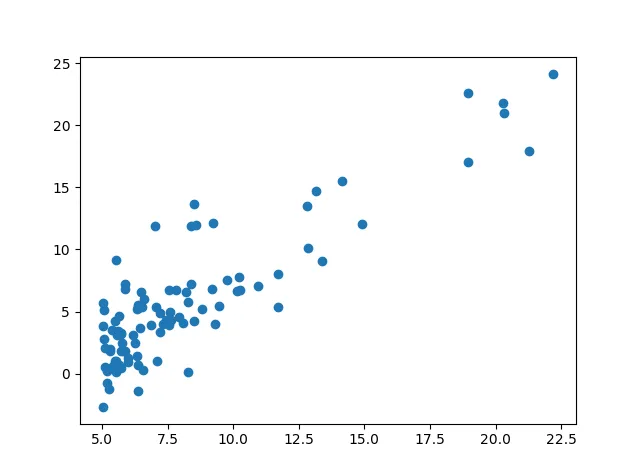
我得到的图像如下,没有显示最佳拟合线,而且当我打印“prediction”的值时,它显示与“y_values”相同的值。
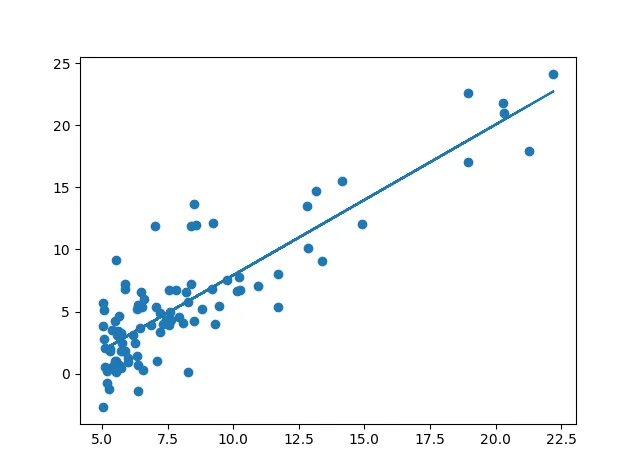
 相反,当我使用以下代码时,我得到了回归线。
相反,当我使用以下代码时,我得到了回归线。#read data
dataframe = pd.read_csv('challenge_dataset.txt')
dataframe.columns=['Brain','Body']
x_values=dataframe[['Brain']]
y_values=dataframe[['Body']]
提前致谢。
.reshape(1,-1)的原因是什么? - ImportanceOfBeingErnestx_values=np.array(dataframe['Brain'],dtype=np.float64).reshape(1,-1)这里我将“Brain”这一列的值以一维数组的形式取出来,虽然可以用二维数组表示,但是我当时只是在做实验。 - Mayank Raj.reshape(1,-1)会发生什么? - ImportanceOfBeingErnest