我一直在尝试生成牛顿迭代法分形的雅可比theta函数 - 我用mpmath尝试了很长时间,所以我尝试用C编写它。
用于生成以下图像的源代码在这里:http://owen.maresh.info/allegra.c,可以使用gcc allegra.c -o allegra -lm进行编译,然后应该调用./allegra > jacobi.pnm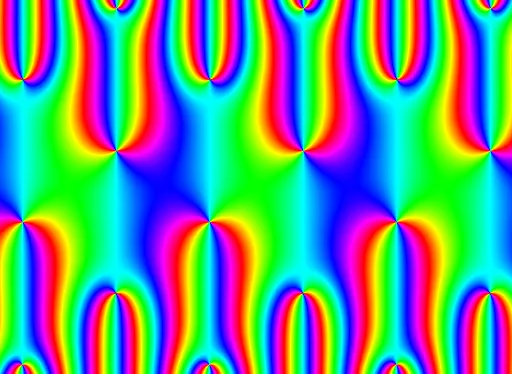
(来源:maresh.info)
所以: * 有没有办法加速评估 - 这需要半个小时的墙时间才能产生这个图像?(我想能够快速生成不同名称的这些图像,以便我可以制作电影) * 我知道我在θ函数定义中犯了一个错误,但我很难找到间断的原因。
供参考,此图像是通过对ϑ3(z,0.001-0.3019*i)进行标准牛顿迭代得到的。
用于生成以下图像的源代码在这里:http://owen.maresh.info/allegra.c,可以使用gcc allegra.c -o allegra -lm进行编译,然后应该调用./allegra > jacobi.pnm
(来源:maresh.info)
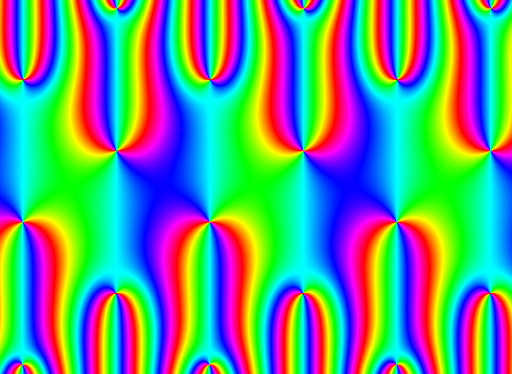{kind=link}
所以: * 有没有办法加速评估 - 这需要半个小时的墙时间才能产生这个图像?(我想能够快速生成不同名称的这些图像,以便我可以制作电影) * 我知道我在θ函数定义中犯了一个错误,但我很难找到间断的原因。
供参考,此图像是通过对ϑ3(z,0.001-0.3019*i)进行标准牛顿迭代得到的。
clangC编译器编译会比使用gcc编译速度变慢的情况吗? - Brian Swifticc生成的代码比gcc运行速度快了7倍以上,这真是令人印象深刻。(另外感谢提到icc,我之前不知道英特尔在 Linux 上免费提供非商业用途的开发工具)。 - Brian Swift