我目前正在使用ggplot绘制多个回归模型的一阶差分分布。为了便于解释差异,我想标记每个分布的2.5%和97.5%百分位数。由于我将要做很多图,并且数据分组在两个维度(模型和类型)中,我想在ggplot环境中定义和绘制相应的百分位数。使用facet将分布绘制到我想要的位置,但不包括百分位数。当然,我可以更加手动地进行操作,但我希望能找到一个解决方案,在这个解决方案中我仍然能够使用
我尝试过两种方法来添加分位数。第一种方法会产生错误信息:
我想知道在ggplot2环境中是否有一种方法来绘制每个子组的特定分位数? 感谢任何意见。
facet_grid,因为这样可以减少与拟合不同图形一起的麻烦。
下面是使用模拟数据的示例:
df.example <- data.frame(model = rep(c("a", "b"), length.out = 500),
type = rep(c("t1", "t2", "t2", "t1"),
length.outh = 250), value = rnorm(1000))
ggplot(df.example, aes(x = value)) +
facet_grid(type ~ model) +
geom_density(aes(fill = model, colour = model))
我尝试过两种方法来添加分位数。第一种方法会产生错误信息:
ggplot(df.example, aes(x = value)) +
facet_grid(. ~ model) +
geom_density(aes(fill = model, colour = model)) +
geom_vline(aes(x = value), xintercept = quantile(value, probs = c(.025, .975)))
Error in quantile(value, probs = c(0.025, 0.975)) : object 'value' not found
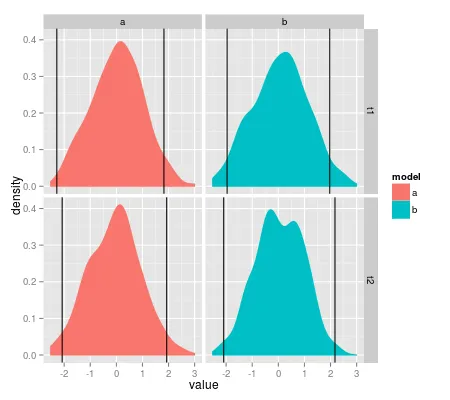
第二个选项可以为整个变量获取分位数,而不是子密度的分位数。也就是说,所有四个密度的绘制分位数是相同的。
ggplot(df.example, aes(x = value)) +
facet_grid(type ~ model) +
geom_density(aes(fill = model, colour = model)) +
geom_vline(xintercept = quantile(df.example$value, probs = c(.025, .975)))
我想知道在ggplot2环境中是否有一种方法来绘制每个子组的特定分位数? 感谢任何意见。