我不知道我在标题中是否表达清楚了自己,但我希望当你看到下面的数字时,它是易于理解的。 首先,这是我的数据:
hydrocarbons average SD type group
N 6,21 4,632774217 PAHs Naphtalenes
N1 4,71 2,43670665 PAHs Naphtalenes
N2 7,6 3,266286228 PAHs Naphtalenes
N3 16,18 11,00643289 PAHs Naphtalenes
N4 18,8 4,59631824 PAHs Naphtalenes
F 16,87 7,022165062 PAHs Fluorenes
F1 16,64 5,721267073 PAHs Fluorenes
F2 18,67 8,467132345 PAHs Fluorenes
F3 22,79 0,988021105 PAHs Fluorenes
P 7,97 0,211647391 PAHs Phenanthrenes
P1 26,66 16,64819987 PAHs Phenanthrenes
P2 21,72 4,416811664 PAHs Phenanthrenes
P3 18,99 4,635405486 PAHs Phenanthrenes
P4 66,28 7,706085861 PAHs Phenanthrenes
D 8,33 0,89862145 PAHs Dibenzothiophenes
D1 8,63 PAHs Dibenzothiophenes
D2 9,57 PAHs Dibenzothiophenes
D3 20,69 3,453922632 PAHs Dibenzothiophenes
D4 32,5 8,191613185 PAHs Dibenzothiophenes
FL 10,37 PAHs Fluoranthenes
PY 10,53 PAHs Fluoranthenes
FL1 24,42 8,886055918 PAHs Fluoranthenes
FL2 42,52 9,466539232 PAHs Fluoranthenes
FL3 51,99 15,77786373 PAHs Fluoranthenes
C 74,28 9,560499532 PAHs Chrysenes
C1 46,56 15,86163409 PAHs Chrysenes
C2 82,85 4,854714782 PAHs Chrysenes
C3 114,42 41,70884318 PAHs Chrysenes
nC-10 2,24 alkanes
nC-11 2,24 alkanes
nC-12 4,85 1,414267191 alkanes
nC-13 5,54 0,089306765 alkanes
nC-14 6,81 0,241222891 alkanes
nC-15 5,56 alkanes
nC-16 5,95 alkanes
nC-17 5,82 alkanes
nC-18 5,7 alkanes
nC-19 6,41 alkanes
nC-20 7,36 alkanes
nC-21 6,24 alkanes
nC-22 6,07 alkanes
nC-23 6,35 alkanes
nC-24 7,32 alkanes
nC-25 6,6 2,215395794 alkanes
nC-26 5,97 1,839829721 alkanes
nC-27 6,51 1,972060107 alkanes
nC-28 7,57 1,797509743 alkanes
nC-29 8,37 3,004883333 alkanes
nC-30 9,05 3,503601406 alkanes
nC-31 10,27 4,242811665 alkanes
nC-32 11,5 5,087821955 alkanes
nC-33 14,31 8,085948386 alkanes
nC-34 16,96 10,10105484 alkanes
nC-35 20,52 14,1878649 alkanes
nC-36 21,88 13,40071226 alkanes
n-C5 (Pentane) 10,63 1,715015757 VOCs
n-C6 (Hexane) 1,74 0,859880844 VOCs
n-C7 (Heptane) 9,62 4,316473516 VOCs
n-C9 (Nonane) 2,34 0,044641 VOCs
Benzene 23,51 0,631882255 VOCs
Toluene 18,48 2,369137637 VOCs
Ethylbenzene 7,55 7,171631537 VOCs
m-Xylene 12,53 7,250491275 VOCs
p-Xylene 15,21 1,800247445 VOCs
o-Xylene 21,96 2,184177383 VOCs
Propylbenzene 12,8 15,31136895 VOCs
n-Butylbenzene 9,33 5,486543125 VOCs
n-Pentylbenzene 6,77 0,420247353 VOCs
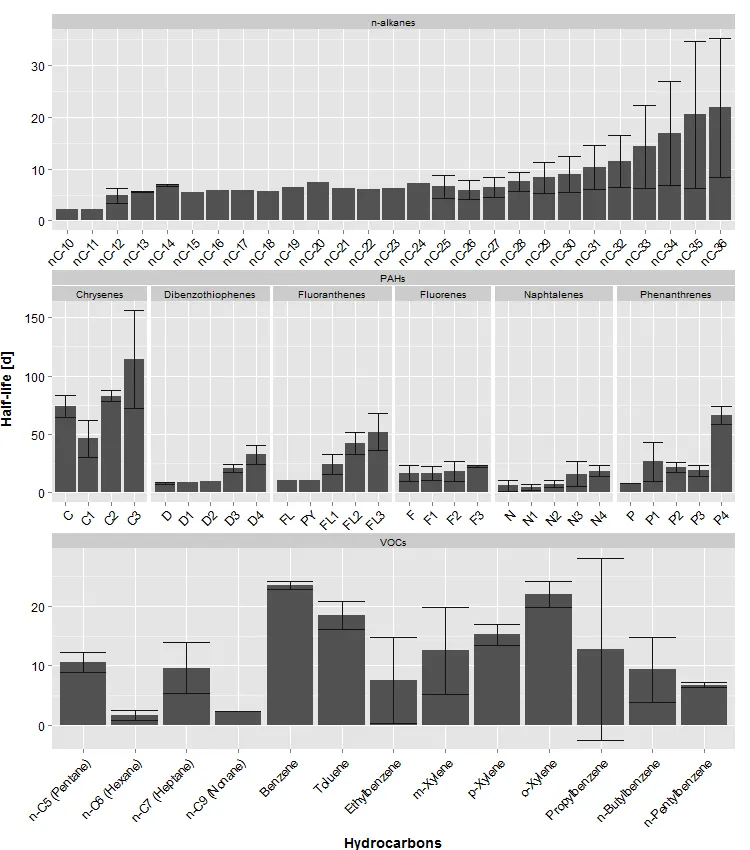
我想绘制我的碳氢化合物的“平均”半衰期,并根据“类型”进行分面。然而,只有对于“PAHs”类型,我希望按“组”进行附加分面。我能够编写和绘制的最佳代码是以下图像,但它并不完全符合我的要求:
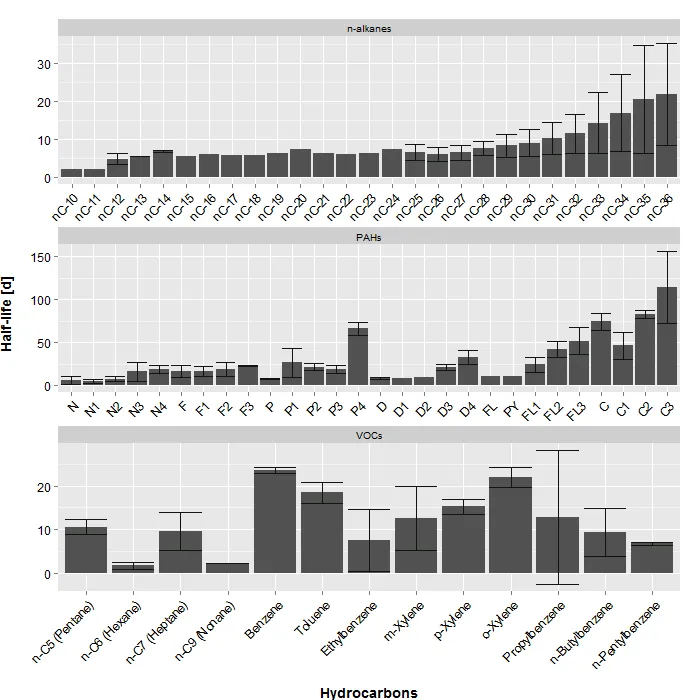 这是我正在使用的代码:
这是我正在使用的代码:all <- read.delim2("E#6-results_chemistry.txt", header=TRUE)
library(ggplot2)
all$hydrocarbons <- factor(all$hydrocarbons, levels = all$hydrocarbons) #keeps the order of x-axis same as in table
levels(all$type)[levels(all$type)=="alkanes"] <- "n-alkanes" #if needed to change specific labels in a column
ggplot(all, aes(x=hydrocarbons, y=average)) +
geom_bar(position = position_dodge(), stat="identity", fill="gray32") +
geom_errorbar(aes(ymin=average-SD, ymax=average+SD), color="gray8") +
facet_wrap(~type, scales="free", ncol=1) +
ylab("Half-life [d]") + xlab("Hydrocarbons") +
theme(axis.text.x=element_text(size=12, color="black", angle=45, hjust=1),
axis.title.x = element_text(size=14, face="bold", vjust=-0.7),
axis.title.y = element_text(size=14, face="bold", vjust=2),
axis.text.y = element_text(size=12, colour="black"))
现在的问题是,是否可以制作一个图形,在现有的一个中添加一个额外的面部条,仅针对“PAHs”类型,根据“组”进行分组?图形可能看起来像这样:
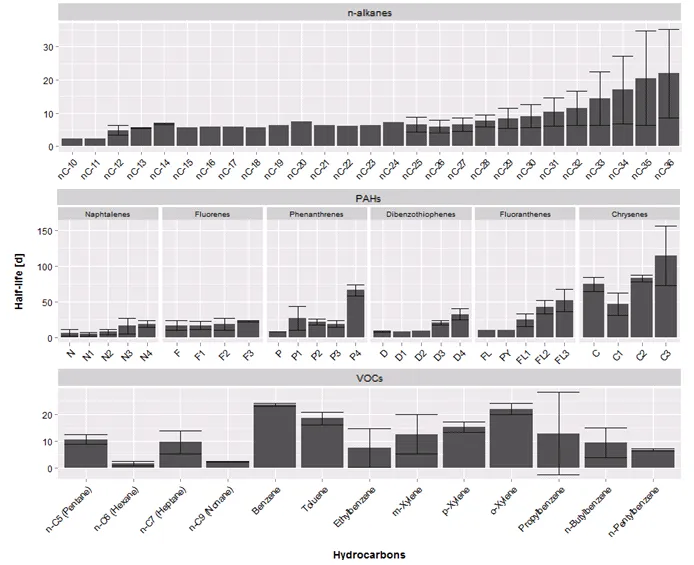 如果可能的话,对于“PAHs”,我也可以制作第二个x轴,根据“组”进行排列。
如果可能的话,对于“PAHs”,我也可以制作第二个x轴,根据“组”进行排列。谢谢, Deni