我最近偶然发现了ggplot2中一些奇怪的行为。以下是代码:
创建一个数据集,其中包含一个数字列和一个因子列,每个类别中都有相同数量的事件:
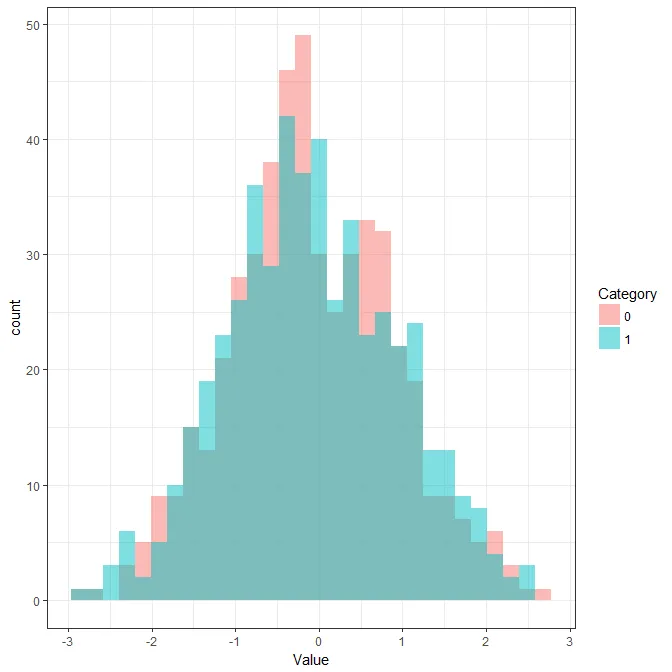
这看起来非常奇怪。两个直方图的箱宽度看起来相等,正如它们应该的那样,但事件的总计数不相等,而它们应该是相等的。实际上,类别0的直方图是整个数据集的直方图:
N <- 1000
coin <- rep(c(0,1),N/2)
N1 <- sum(coin)
N0 <- sum(1-coin)
values <- rep(0,N)
values[coin==0] <- rnorm(N0,mean=0,sd=1)
values[coin==1] <- rnorm(N1,mean=0,sd=1)
dat = data.frame('Value'=values,'Category'=as.factor(coin))
创建一个数据集,其中包含一个数字列和一个因子列,每个类别中都有相同数量的事件:
> summary(dat)
Value Category
Min. :-3.901785 0:500
1st Qu.:-0.669807 1:500
Median : 0.020031
Mean :-0.008229
3rd Qu.: 0.650803
Max. : 3.195819
然而,将按类别分解的价值列进行绘制时,类别1的标准化要比类别0高得多:
ggplot(dat,aes(x=Value,fill=Category)) + geom_histogram(alpha=0.5) + theme_bw()
这看起来非常奇怪。两个直方图的箱宽度看起来相等,正如它们应该的那样,但事件的总计数不相等,而它们应该是相等的。实际上,类别0的直方图是整个数据集的直方图:
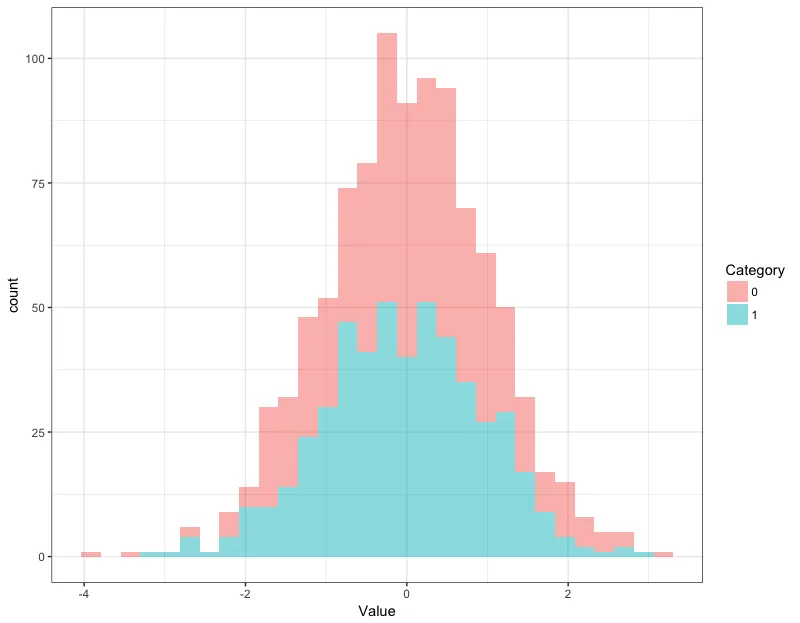
ggplot(dat,aes(x=Value)) + geom_histogram(alpha=0.5) + theme_bw()
这是 ggplot2 的 bug 吗?还是我犯了一些我没有注意到的错误?顺便说一下,如果我将类别0和1替换为'A'和'B',我得到相同的结果。
系统详细信息:
- Mac OS X High Sierra
- R版本3.4.0(2017-04-21)
- ggplot2_2.2.1