我正在阅读一个公式:
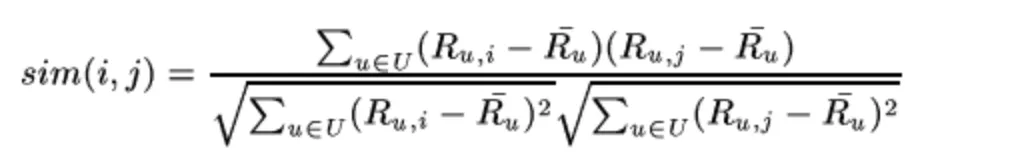
这个公式是用于计算余弦相似度的。我认为这看起来很有趣,于是我创建了一个numpy数组,该数组以用户ID作为行,物品ID作为列。例如,让M 是这个矩阵:
M = [[2,3,4,1,0],[0,0,0,0,5],[5,4,3,0,0],[1,1,1,1,1]]
这里矩阵中的条目是人们给项目 i 的评分,基于行 u 和列 i。我想在项目(行)之间计算此矩阵的余弦相似度。我相信这应该会产生一个 5 x 5 的矩阵。我尝试过了。
df = pd.DataFrame(M)
item_mean_subtracted = df.sub(df.mean(axis=0), axis=1)
similarity_matrix = item_mean_subtracted.fillna(0).corr(method="pearson").values
然而,这似乎不太对。