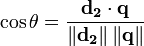TF-IDF仅是衡量文本中标记重要性的一种方法;它是将文档转化为数字列表的常见方式(术语向量提供了您正在获取余弦的角的一条边)。
要计算余弦相似度,您需要两个文档向量;向量用索引表示每个唯一术语,并且该索引处的值是该术语对文档和文档相似性概念的重要性的某种度量。
您可以简单地计算文档中每个术语出现的次数(术语频率),并将整数结果用作向量中的术语得分,但结果不会很好。极为常见的术语(例如“is”、“and”和“the”)会导致许多文档看起来相似。(这些特定示例可以通过使用
停用词列表来处理,但是其他常见术语不足以被视为停用词,会导致相同类型的问题。在Stackoverflow上,“question”可能属于此类别。如果您正在分析烹饪食谱,则可能会遇到“egg”这个词的问题。)
TF-IDF通过考虑每个术语在一般情况下出现的频率(文档频率)来调整原始术语频率。逆文档频率通常是术语出现的文档数除以文档总数的对数(图片来源于维基百科)。
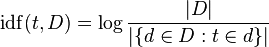
请注意,'log'只是一个微小的细节,帮助长期运作--当其参数增加时,它会增长,因此如果术语很少,则IDF将很高(许多文档除以非常少的文档),如果术语很常见,则IDF将很低(许多文档除以许多文档~=1)。
假设您有100个食谱,除了一个不需要鸡蛋,现在您有另外三个包含单词“egg”的文档,第一个文档中出现一次,第二个文档中出现两次,第三个文档中出现一次。“egg”每个文档中的词频为1或2,文档频率为99(或者,可以说是102,如果计算新文档。我们坚持使用99)。
'egg'的TF-IDF为:
1 * log (100/99) = 0.01
2 * log (100/99) = 0.02
1 * log (100/99) = 0.01
这些数字都比较小,相比之下,让我们来看另一个词,它只在你的100个食谱语料库中出现了9次:“芝麻菜”。它在第一个文档中出现了两次,在第二个文档中出现了三次,在第三个文档中则没有出现。
“芝麻菜”的TF-IDF值为:
1 * log (100/9) = 2.40 # document 1
2 * log (100/9) = 4.81 # document 2
0 * log (100/9) = 0 # document 3
"'芝麻菜'对于文档2非常重要,至少与'鸡蛋'相比如此。谁在乎鸡蛋出现了多少次?每个东西都含有鸡蛋!这些术语向量比简单计数更具信息性,并且它们将导致文档1和2(关于文档3)比使用简单的术语计数更接近。在这种情况下,可能会得出相同的结果(嘿!我们只有两个术语),但差异会更小。
这里的要点是TF-IDF生成更有用的文档中术语的度量,因此您不会专注于非常常见的术语(停用词,“鸡蛋”),而忽视重要的术语(“芝麻菜”)。"