我有以下格式的数据:
| | Measurement 1 | | Measurement 2 | |
|------|---------------|------|---------------|------|
| | Mean | Std | Mean | Std |
| Time | | | | |
| 0 | 17 | 1.10 | 21 | 1.33 |
| 1 | 16 | 1.08 | 21 | 1.34 |
| 2 | 14 | 0.87 | 21 | 1.35 |
| 3 | 11 | 0.86 | 21 | 1.33 |
我使用以下代码从这些数据中生成一个matplotlib折线图,该图显示标准偏差作为填充区域,如下所示:
def seconds_to_minutes(x, pos):
minutes = f'{round(x/60, 0)}'
return minutes
fig, ax = plt.subplots()
mean_temperature_over_time['Measurement 1']['mean'].plot(kind='line', yerr=mean_temperature_over_time['Measurement 1']['std'], alpha=0.15, ax=ax)
mean_temperature_over_time['Measurement 2']['mean'].plot(kind='line', yerr=mean_temperature_over_time['Measurement 2']['std'], alpha=0.15, ax=ax)
ax.set(title="A Line Graph with Shaded Error Regions", xlabel="x", ylabel="y")
formatter = FuncFormatter(seconds_to_minutes)
ax.xaxis.set_major_formatter(formatter)
ax.grid()
ax.legend(['Mean 1', 'Mean 2'])
输出:
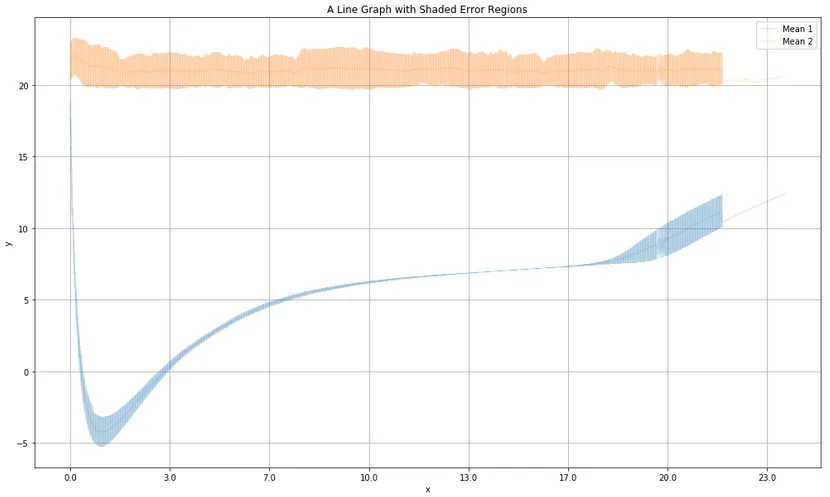 这种方法似乎很混乱,只有在我有大量数据时才会产生阴影效果。 从我拥有的数据框中生成带有阴影误差区域的折线图的正确方法是什么? 我已经看过 Plot yerr/xerr as shaded region rather than error bars,但无法将其适应我的情况。
这种方法似乎很混乱,只有在我有大量数据时才会产生阴影效果。 从我拥有的数据框中生成带有阴影误差区域的折线图的正确方法是什么? 我已经看过 Plot yerr/xerr as shaded region rather than error bars,但无法将其适应我的情况。
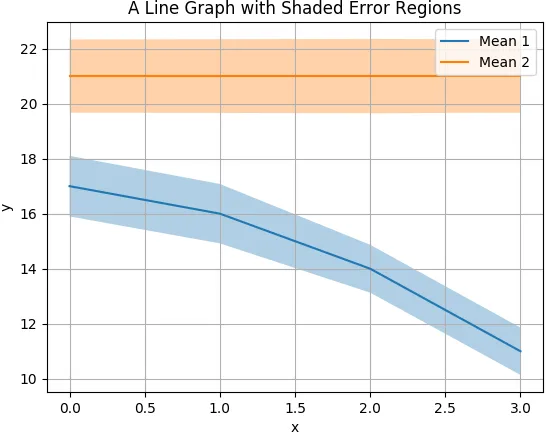
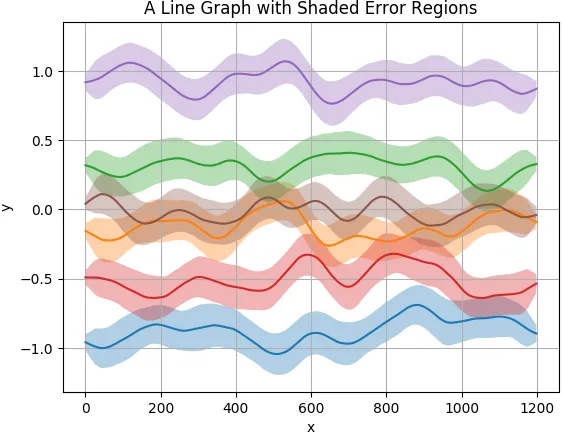
mean_temperature_over_time.swaplevel(0,1,axis=1).stack().reset_index().sort_values("Measurement")来获取我的格式,或者你可以使用类似于for i, m in mean_temperature_over_time.groupby(level=0, axis=1): print(m[i].Mean)的方式在你的数据框中进行迭代。 - filippo