我在R中实现了多元线性回归的梯度下降算法。我想看看是否可以使用现有的方法运行随机梯度下降算法。我不确定这是否真的是低效的。例如,对于每个α值,我想执行500次SGD迭代,并能够指定每次迭代中随机选择的样本数量。这样做将很好地展示样本数量对结果的影响。但是,我遇到了小批量处理的问题,并且希望能够轻松绘制结果。以下是我目前的进展:
# Read and process the datasets
# download the files from GitHub
download.file("https://raw.githubusercontent.com/dbouquin/IS_605/master/sgd_ex_data/ex3x.dat", "ex3x.dat", method="curl")
x <- read.table('ex3x.dat')
# we can standardize the x vaules using scale()
x <- scale(x)
download.file("https://raw.githubusercontent.com/dbouquin/IS_605/master/sgd_ex_data/ex3y.dat", "ex3y.dat", method="curl")
y <- read.table('ex3y.dat')
# combine the datasets
data3 <- cbind(x,y)
colnames(data3) <- c("area_sqft", "bedrooms","price")
str(data3)
head(data3)
################ Regular Gradient Descent
# http://www.r-bloggers.com/linear-regression-by-gradient-descent/
# vector populated with 1s for the intercept coefficient
x1 <- rep(1, length(data3$area_sqft))
# appends to dfs
# create x-matrix of independent variables
x <- as.matrix(cbind(x1,x))
# create y-matrix of dependent variables
y <- as.matrix(y)
L <- length(y)
# cost gradient function: independent variables and values of thetas
cost <- function(x,y,theta){
gradient <- (1/L)* (t(x) %*% ((x%*%t(theta)) - y))
return(t(gradient))
}
# GD simultaneous update algorithm
# https://www.coursera.org/learn/machine-learning/lecture/8SpIM/gradient-descent
GD <- function(x, alpha){
theta <- matrix(c(0,0,0), nrow=1)
for (i in 1:500) {
theta <- theta - alpha*cost(x,y,theta)
theta_r <- rbind(theta_r,theta)
}
return(theta_r)
}
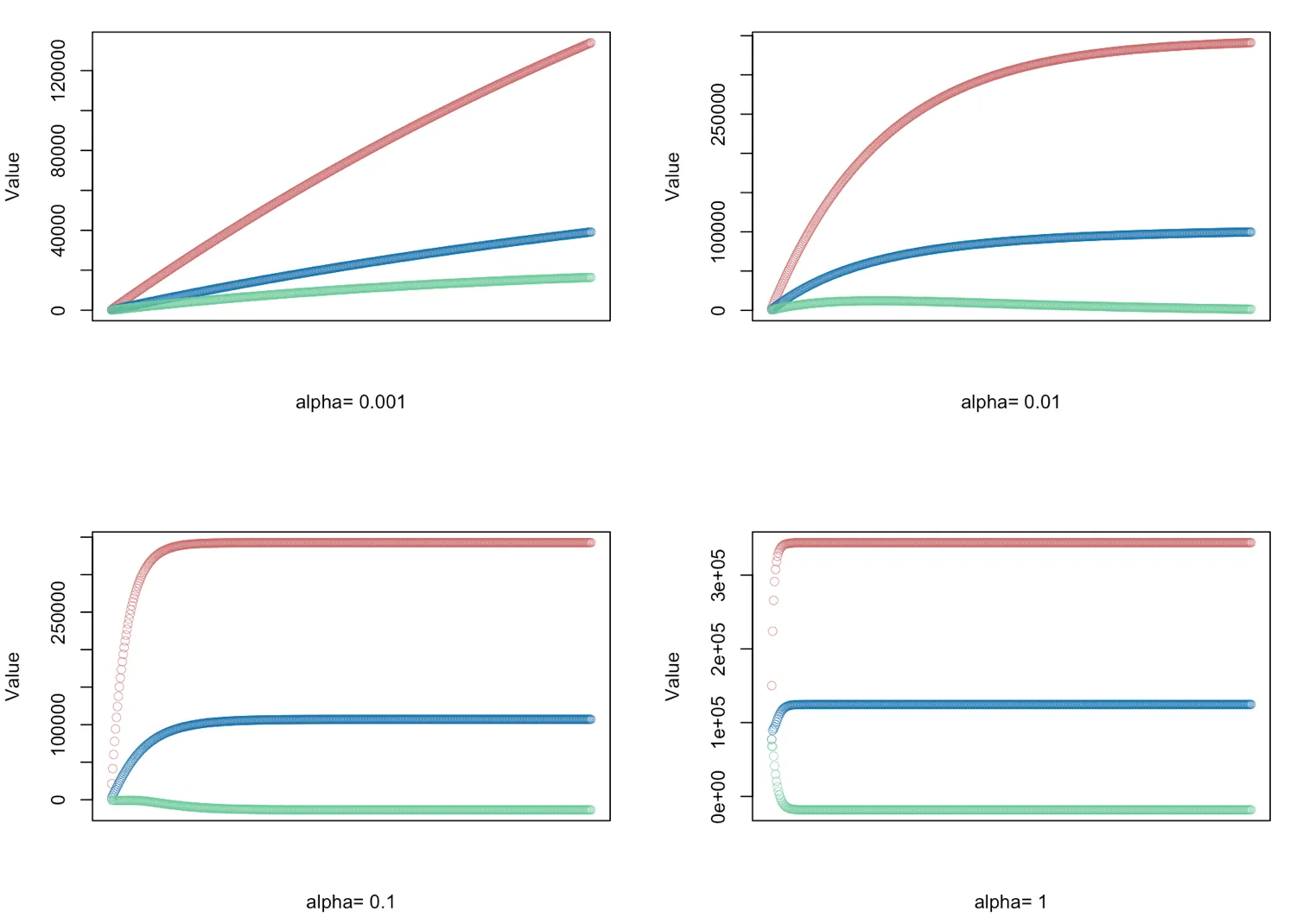
# gradient descent α = (0.001, 0.01, 0.1, 1.0) - defined for 500 iterations
alphas <- c(0.001,0.01,0.1,1.0)
# Plot price, area in square feet, and the number of bedrooms
# create empty vector theta_r
theta_r<-c()
for(i in 1:length(alphas)) {
result <- GD(x, alphas[i])
# red = price
# blue = sq ft
# green = bedrooms
plot(result[,1],ylim=c(min(result),max(result)),col="#CC6666",ylab="Value",lwd=0.35,
xlab=paste("alpha=", alphas[i]),xaxt="n") #suppress auto x-axis title
lines(result[,2],type="b",col="#0072B2",lwd=0.35)
lines(result[,3],type="b",col="#66CC99",lwd=0.35)
}
是否更实际找到使用sgd()的方法?我似乎无法通过sgd包获得我所寻求的控制水平。
model.control和sgd.control似乎由sgd:::valid_model_control和sgd:::valid_sgd_control控制,尽管我没有看到有关观测数量的选项。鉴于sgd在批量大小==1时保证最优,可能没有选项。通常,批量大小仅指定为控制学习时间(计算时间而不是迭代次数)...由于该软件包正在积极开发中,建议您与作者提出问题...即使您使用下面rawr的包装器。 - alexwhitworth